引言
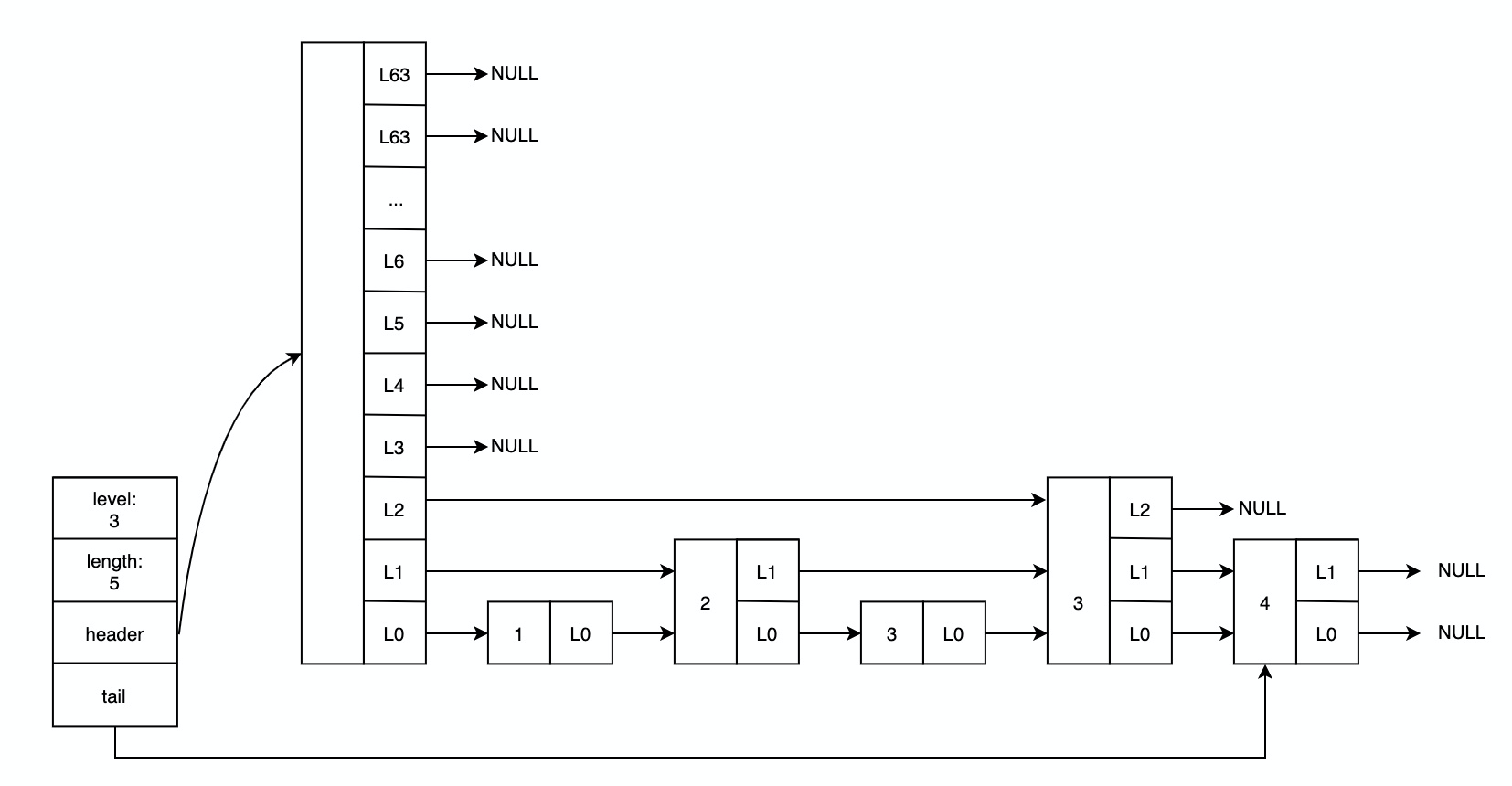
读过 Redis 源码的童鞋,想必会知道 zset 实现时,使用了「跳表」(Skiplist)这种数据结构吧。它的原理非常容易理解,如果对链表比较熟悉,那么也会很容易理解「跳表」的工作原理(核心:有序链表 + 分层)。当然,本文并不会详细讲解「跳表」的工作原理,以及对于 Redis 跳表源码的详细分析。因为已经有前辈们产出了非常丰富的文章来讲解 Redis 跳表,需要的话,推荐阅读 这篇文章 了解更多细节。
总的来说,Redis 的 zset 实现中,选用「跳表」的主要原因如下:
- 原理清晰易懂,且容易实现,方便维护:对比下平衡树或者红黑树(可能就像 Raft v.s. Paxos 的感觉一样),不管是原理还是实现都简单了很多。平衡树或者红黑树在实现时,还要时刻维护节点关系,必要时还需要执行树的左旋或者右旋来保持平衡;
- 拥有媲美平衡树或者红黑树的查询效率:插入、删除、查找的平均时间复杂度可以达到 O(logN)。
当然,相对于 William Pugh 在他的论文中所描述的「跳表」算法而言,作者在实现 Redis 中的「跳表」时,给它加了点「料」:
- 允许重复的分数存在;
- 在进行比较时,不仅会比较 score,还会考虑关联的数据;
- 添加了一个回退指针,从而构成了一个双向链表(level[0]),便于倒序遍历链表(
ZREVRANGE)使用。
好了,废话完毕。接下来进入正题,看看如何使用 Go 语言来实现「跳表」吧(贴代码模式开启~)。
跳表实现
以下仅仅列出了几个比较有趣且关键的方法实现,即:插入、删除和更新分数。完整的实现源码可以参考 这里 或者 这里,包含了比较详细的单元测试。
数据结构定义
需要说明的是,为了简单起见,假设存储的元素是字符串类型(要是使用 interface{} 的话,又得加些代码支持元素之间的比较了)。但是在 Redis 中,实际的 element 类型是 sds。
1 | const ( |
辅助方法
考虑到在实现时,经常需要比较 score 和 element,所以这里直接给 Node 实现了一些比较方法,便于使用。
1 | func (node *Node) Compare(other *Node) int { |
插入元素
1 | // Insert 向跳表中插入一个新的元素。 |
删除元素
1 | // Delete 用于删除跳表中指定的节点。 |
更新分数
1 | // UpdateScore 用于更新节点的分数。该函数会保证更新分数后, |
总结
俗话说,「说起来容易,做起来难」。在实现「跳表」的时候感受颇深,似乎看完 Redis 的「跳表」源码和网上诸多前辈编写的文章后,自以为懂得了原理(可能确实懂了),但是在具体实现的时候还是踩了不少坑。比如,空指针引起 panic;i-- 写成了 i++ 导致查找失败;一些边界情况的判断等。总之,细节决定成败,需要在保持思路清晰的同时,更加谨慎一些才能写出足够健壮的代码来。当然,这期间自然少不了单元测试的助攻,否则有很多问题可能都没法暴露出来~