引言
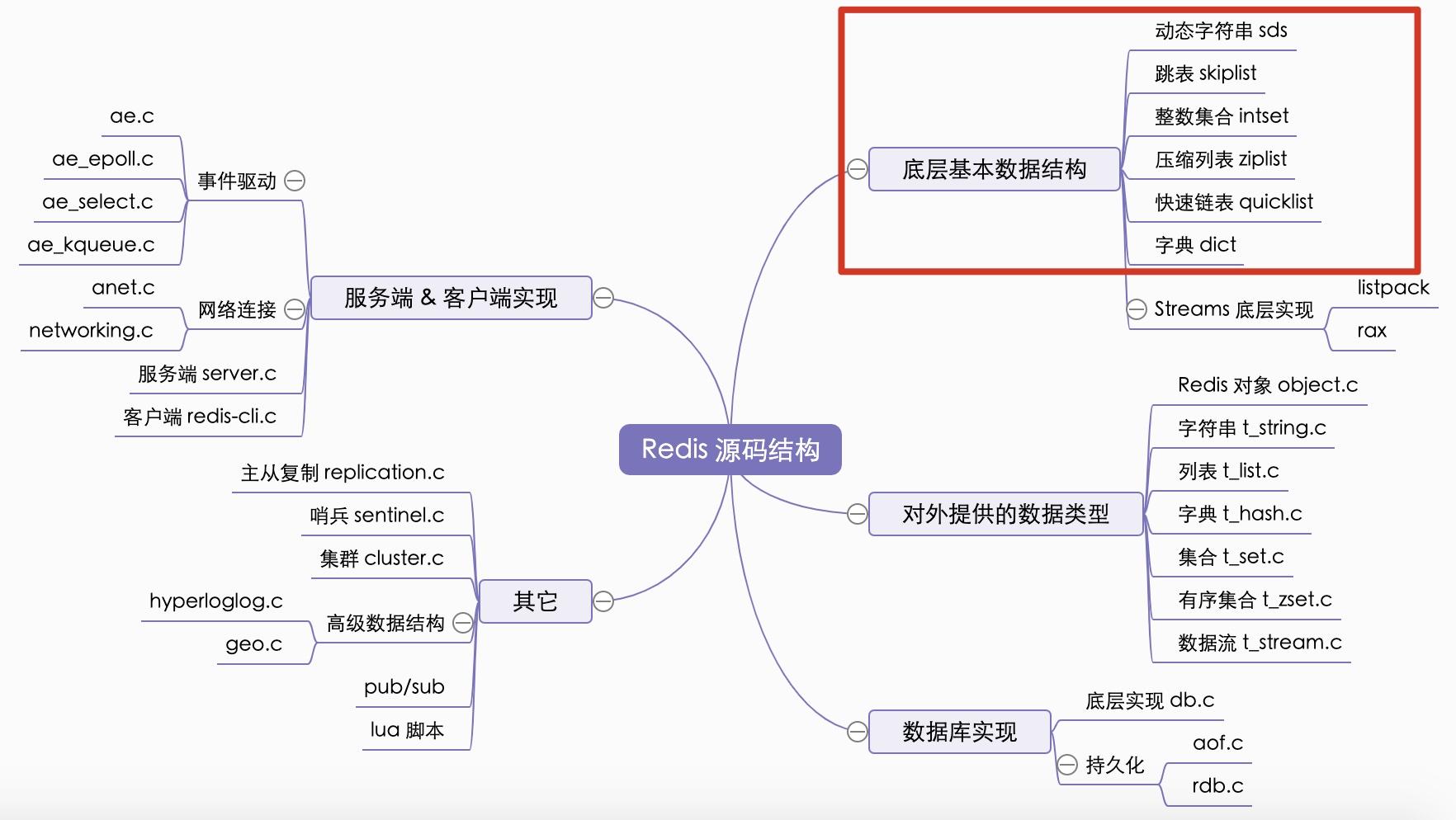
Redis 底层的基础数据结构包括:动态字符串(sds)、跳表(skiplist)、压缩列表(ziplist)、字典(dict)、整数集合(intset),快速链表(quicklist)等,t_hash,t_set, t_zset, t_list 等对外类型的内部实现都依赖于这些数据结构,所以非常值得学习。
在学习每种数据结构时,需要重点关注如下几个问题:
- 为什么这样设计,做了什么样的权衡?比如,有些数据结构是为了节约内存而设计的,所以会牺牲一定的查找效率;
- 每种数据结构的基本特点是什么?具体在什么场景下应用到?
- 一些数据结构接口的平均时间复杂度是什么?
- 很多数据结构在上层使用时,会根据需要选择,必要时会进行转换。需要了解转换的时机和触发的条件是什么?
- 某些数据结构内部会按需扩容或者缩容,需要关注它们扩容或者缩容的策略如何?什么情况下触发?
本文的源码学习笔记是基于 Redis 5.0.7 版本做的,自己做了些中文注释,推送到了 redis comment-src 分支,参考书籍为《Redis 5 源码设计与分析》。
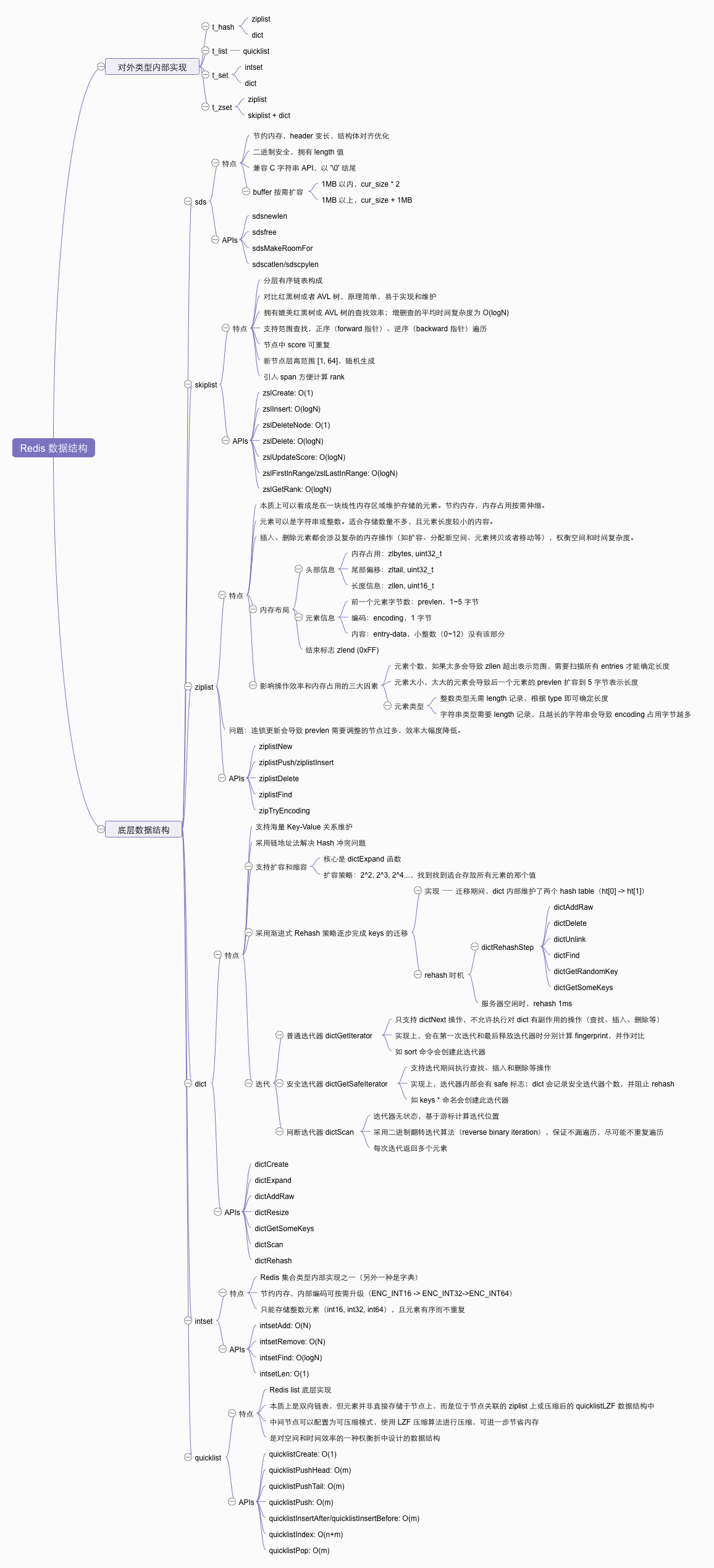
做了一个简单的思维导图,简单总结了各个数据结构的基本特点和一些值得阅读源码的 APIs,如果想要快速了解的话,可以直接跳到本文最后一节查看~
动态字符串
动态字符串(SDS, Simple Dynamic String)是 Redis 中最常用的数据类型之一,可以用来存储字符串和整数。并且它是二进制安全的,还兼容 C 语言字符串的结束符 ‘\0’,所以部分 C 标准库中的字符串函数也可以对 SDS 进行操作。
动态字符串元信息及存储字符串的 buf 是由 sdshdr* 维护的,其定义如下:
1 | // __attribute__ ((__packed__)) 使用这种方式,要求编译器编译时,按照实际的字节数进行对齐。 |
关于 SDS 的几个问题:
- 如何兼容 C 语言字符串标准? SDS 返回的就是指向存储字符串 buf 的指针,且以 ‘\0’ 结尾。
- 如何节约内存? SDS 中根据字符串长度,提供了不同类型的结构体表示(sdshdr5, sdshdr8, sdshdr16, sdshdr32, sdshdr64),并且结构体中的字段按照单字节对齐(
((__packed__)))进一步减少因默认字节对齐方式带来了内存消耗;同时按照单字节对齐,也方便基于 header 指针计算出柔性数组的指针。 - 如何做到二进制安全? SDS Header 结构体中拥有
len字段,记录了实际字符串的长度(不含结束符),因此在读取的时候可以确切地知道在哪儿停止,不会受到中间的 ‘\0’ 影响。 - SDS 在创建空字符串时,为何将 sdshdr5 转成 sdshdr8? 考虑到 sdshdr5 可能需要频繁扩容,导致内存复制开销。使用 sdshdr8 可以有效缓解。
- SDS 对于短字符串为何使用 sdshdr5? 很简单,还是为了节省内存空间,多数的字符串可能都是短字符串(长度 32 以内)。
- SDS 在写入时可能会扩容,那么它的扩容策略是怎样的?它的策略比较简单,如果 buf 剩余空间(alloc-len)能够放下新增的字符串长度,则不会有实质的扩容发生;如果剩余空间不够,则需要看 len+newLen 的长度值,如果小于 1MB,则按照 2 倍扩容;否则每次增加 1MB。在扩容后,还要看新的 header 类型(flags 字段表示)是否和之前一样,如果一样,则直接使用 realloc 原地扩容即可;否则需要使用 malloc 开辟新空间,并使用
memcopy复制数据。完成扩容后,需要更新 SDS 的一些统计信息,并返回新的 buf 指针(也可能指向原来位置,具体看扩容时的策略执行)。
核心源码
详细的源码注释参见 这里
1 | // sdsnewlen 创建一个新的 sds 对象,并使用 init 指向的内容初始化 |
跳表(skiplist)
跳表是 Redis 集合(zset)底层的实现方式之一(另一种是 ziplist)。跳表的特点如下:
- 原理简单,实现难度远低于平衡树(红黑树);
- 对于查找、插入和删除,平均 O(logN) 时间复杂度,效率和红黑树相当;
- 内存开销相对平衡树并没有特别大;
- 特别容易实现 Redis zset 中范围查询。
跳表核心要素:分层 + 有序链表。
跳表查找过程描述:从最上层依次向后查找,如果本层的 next 节点大于要查找的值,或者 next 节点为 NULL,则从本节点开始,降低一层继续往后查找。如果找到目标节点,则返回;否则返回 NULL。
此前使用 Go 语言尝试实现了下 Redis 跳表,相关文章参见 Go 语言实现 Redis 跳表,源码及注释参见 此处。感兴趣的童鞋可以阅读下~
Redis 跳表实现特点
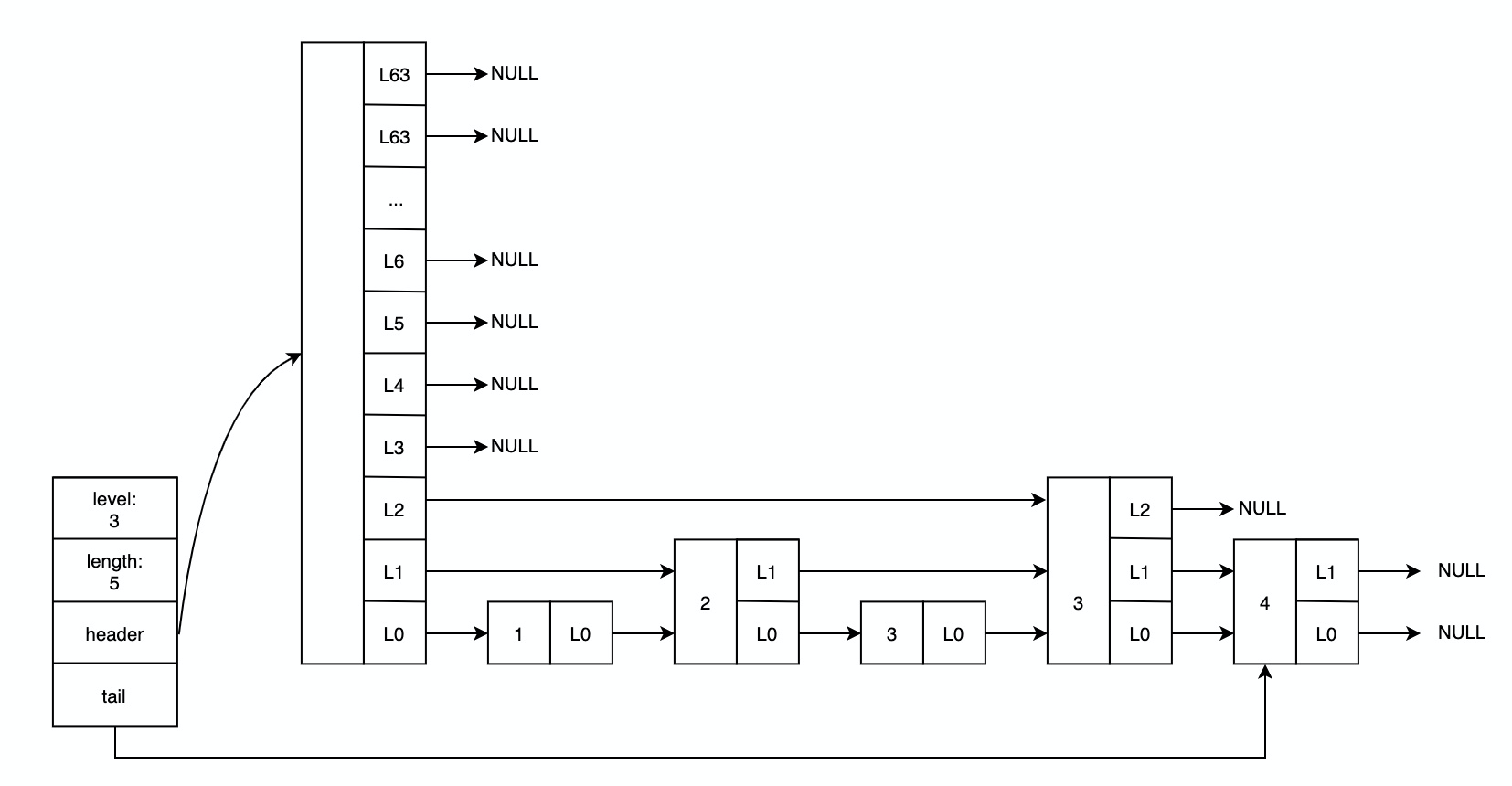
- 最多有 64 层,可以表示 2^64 个元素;
- 拥有 backward 后退指针,方便反向遍历;
- 添加了 span 字段,记录 forward 指向的节点和当前节点的间隔。span 越大,跳过的节点会越多。在计算排名(rank)时,就可以通过 span 计算得到;
- 新增节点时,层高是通过
zlsRandomLevel()函数随机生成的,范围是 [1, 64]。但是该函数会保证越高 level 值的出现的概率越低。节点的层高确定后,将不会改边; - 节点中的 score 允许重复。
跳表的具体应用
zset 会使用跳表存储数据,但是它会根据配置 zset-max-ziplist-entries 128 和 zset-max-ziplist-value 64 值来确定该使用跳表还是 ziplist。另外,在新增元素时,如果原先是 ziplist,当临界条件达到时,会被转换成 skiplist,而且转变后就不可逆了。
核心源码
与跳表相关的几个重要的函数作了注释,参见 此处。需要重点关注的函数如下:1
2
3
4
5zskiplist *zslCreate(void)
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele)
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update)
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node)
zskiplistNode *zslUpdateScore(zskiplist *zsl, double curscore, sds ele, double newscore)
在看源码时,会经常看到 update[] 数组,这个数组是用来存放每一层需要被更新的节点(在增加、删除节点时会用到),把它看成 pending_update_nodes 或许会更好理解点。
另外,在增、删、改的时候,都会涉及到 span 的更新,需要仔细斟酌计算逻辑,一不小心就算错了。
压缩列表(ziplist)
压缩表本质上就是一个字节数组,是一种为节约内存而设计的数据结构。可以存储多个元素,且每个元素可以是整数或者字符串(这里其实也可以理解为二进制安全的字节数组)。两端操作(pop/push)时间复杂度为 O(1),但考虑到它每次插入或删除元素时,都需要调整内存(扩容或者缩小内存占用),所以实际的时间复杂度和它占用的内存有关。
ziplist 在散列表、列表和有序集合中均有(直接或间接地)应用。我们可以通过 object encoding <key> 来查看具体的使用的数据结构:
1 | > zadd visitors 1.0 a |
内存布局
在 Redis 的 ziplist.c 中,作者在注释中给出了压缩列表存储布局,并且给出了非常详细的说明和示例,值得阅读。整体来看,压缩列表的内存布局如下:
| 字段名 | 类型 | 说明 |
|---|---|---|
| zlbytes | uint32_t | 压缩表字节长度(包括 zlbytes 自己) |
| zltail | uint32_t | 尾元素相对于压缩列表起始地址的偏移,如此方便快速 pop 最后一个元素 |
| zllen | uint16_t | 表示 entries 的个数,最大有效值为 2^16-2,一旦超出,该值固定为 2^16-1,并且需要遍历整个列表才能得到准确的长度 |
| zlend | uint8_t | 固定为 0xff,表示压缩列表的结尾 |
Entry
接下来,我们看看每个 entry 究竟是什么样子的,如下所示: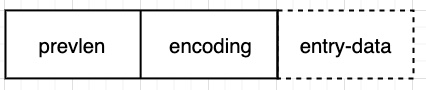
其中,prevlen 表示前一个 entry 的字节数,便于从后向前遍历;encoding 则表示当前 entry 的编码(整数类型?字符串类型?);而 entry-data 则是真实存储内容的部分。当然,为了节约内存,这里的 prevlen 和 encoding 都是变长的,而 entry-data 则可能没有(比如存储小整数 0~12 时)。
默认情况下,prevlen 采用 uint8_t 类型,可表示最多 253 字节长度,超出 253 后,将会使用 5 个字节。
1 | // 常规情况下 |
encoding 字段也比较有趣,它占用多少个字节,和实际要存储的内容有关:
- 如果是字符串类型,则
encoding的前两位表示类型,剩下的则表示字符串的长度:|00pppppp|:表示长度小于 64 字节的字符串,pppppp表示 6 位无符号整数|01pppppp|qqqqqqqq| - 2 字节:表示长度小于 2^14 字节的字符串|10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 字节:表示长度小于 2^32 的字符串
- 如果是整数类型,则
encoding的前两位总是 1,紧接着的两位则表示具体的整数类型:|11000000|:int16|11010000|:int32|11100000|:int64|11110000|:24 位有符号整数|11111110|:8 位有符号整数|1111xxxx|:表示 4 位立即整数(imediate integer),0~12 无符号整数,此时没有entry-data字段了
小结
根据上面描述的 ziplist 编码,我们来看看什么条件下它会占用较多内存?为什么说 ziplist 适合存储个数较少,且长度较短的元素呢?
- 通过
zzlen可知,如果元素个数超出2^16-2时,需要遍历整个 ziplist 元素才可以知道具体的长度,效率自然会降低很多; - 通过
prevlen可知,如果前一个entry超出其表示的范围时(253 字节),就需要由原来的 1 个字节变成 5 字节表示; - 通过
encoding可知,对于字符串类型元素,长度越长,encoding需要占用的字节越多。尤其是在超出2^14-1时,新的encoding还要浪费第一个字节中的后 6 位,而使用后面的 32 位整数来表示字符串长度。
综上所述,影响内存占用和执行效率的主要因素如下:
- 元素个数;
- 元素类型;
- 元素长度。
核心源码
为了方便获得每个 entry 相关的元信息,在 ziplist.c 中定义了一个 zlentry 结构体,但需要注意的是该结构体并非 entry 实际编码的布局。其定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31// zlentry 存在的目的就是保存每个 entry 解码后的元信息。因为实际每次对 length, encoding
// 等进行解码是比较复杂的运算,这里缓存下来也便于后续操作。
// 所以,需要注意的是,zlentry 并非真实的 entry 编码结构。
typedef struct zlentry {
// prevrawlensize 表示 `prevlen` 占用了几个字节来表示前一个 entry 的长度
unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/
// prevrawlen 表示前一个 entry 的实际长度
unsigned int prevrawlen; /* Previous entry len. */
// lensize 表示 `encoding` 占用了几个字节
unsigned int lensize; /* Bytes used to encode this entry type/len.
For example strings have a 1, 2 or 5 bytes
header. Integers always use a single byte.*/
// len 表示 entry 内容真正的长度。如果是字符串,就表示字符串长度;如果是整数
// 则可能的值为 0(4 位小整数),1,2,3,4,8(和具体的 int 类型有关)
unsigned int len; /* Bytes used to represent the actual entry.
For strings this is just the string length
while for integers it is 1, 2, 3, 4, 8 or
0 (for 4 bit immediate) depending on the
number range. */
// headersize 表示整个 header 部分长度:<prevlen> + <encoding>
unsigned int headersize; /* prevrawlensize + lensize. */
// encoding 表示具体的编码方式,如果 `ZIP_STR_*`,`ZIP_INT_*`
// 这里需要注意的是,如果是小整数,还要做范围检查
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
// p 指向元素开头的指针,实际指向的就是 `prevlen` 位置
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;
为了方便理解,画一个示例图如下: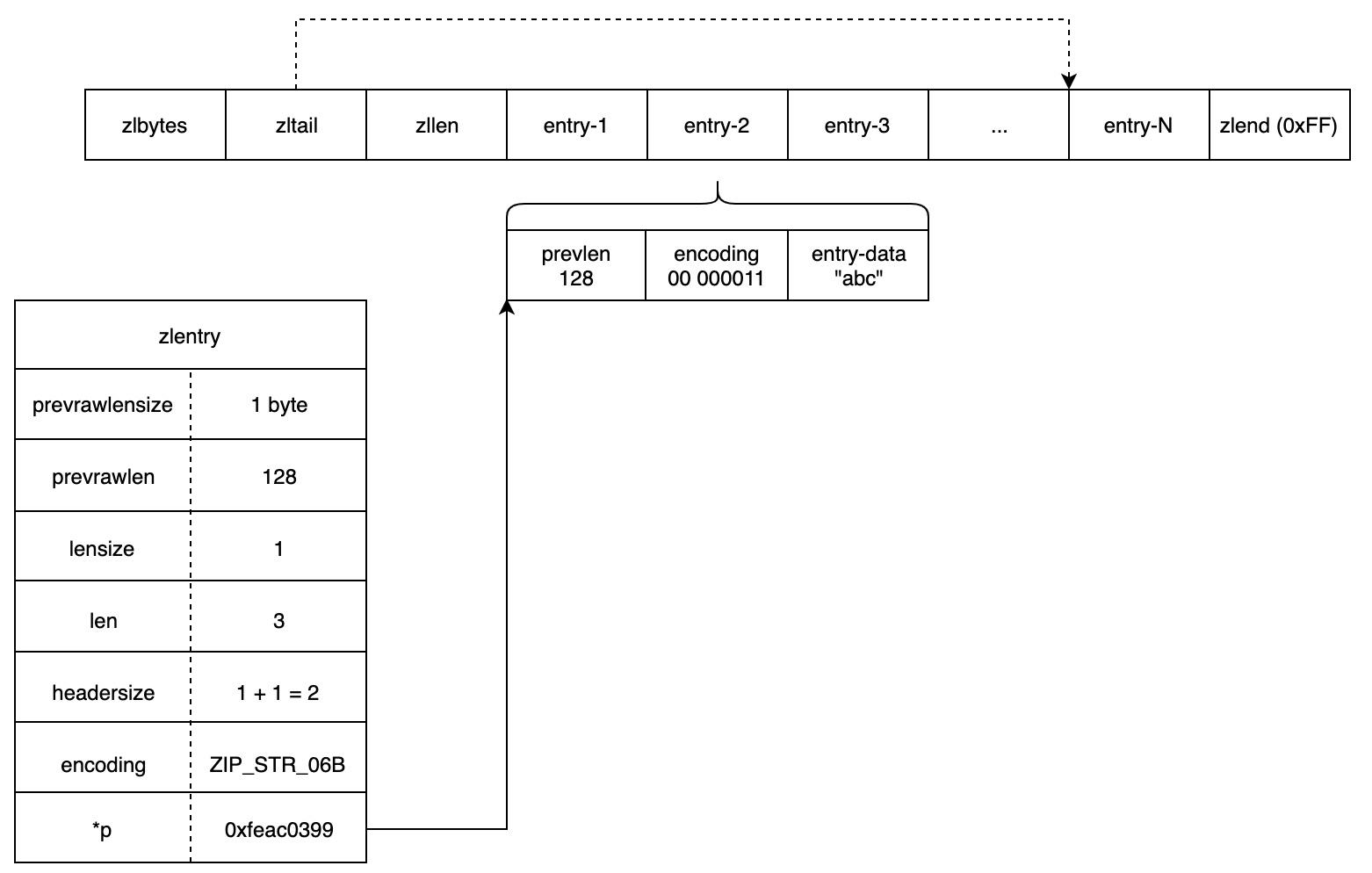
ziplist 相关的源码参见 此处。值得重点关注的几个函数如下:
1 | unsigned char *ziplistNew(void); |
ziplist 中比较晦涩或者枯燥的部分是编码、解码操作;其次,每次增加或者移除元素时,都涉及到很多内存操作(分配空间、内存拷贝)以及 entry header 的调整。想要写出可靠的代码来,还是需要心思缜密,逻辑清晰才可以,大佬们的编码能力实在是太强悍了!
这里需要提一点的是,元素的插入和删除,可能会产生连锁更新问题。也就是说,可能会导致自插入点(或删除点)后续的 entry prevlen 都需要修改(还记得前面提到的 entry prevlen 是变长的吗,所以可能需要将 prevlen 增长到 5 字节容纳更大的值;但是反过来,并没有允许缩容)。不过这种情况,只有在后续元素的大小接近于 ZIP_BIG_PREVLEN 才可能发生,概率比较低,所以实际上也没做什么优化。具体策略的实现可以参考 __ziplistCascadeUpdate():
1 | unsigned char *__ziplistCascadeUpdate(unsigned char *zl, unsigned char *p) |
字典(dict)
字典在 Redis 中是一个非常重要的数据结构,因为 Redis 本身就是一个 Key-Value 数据库。Redis 中的字典实现特点如下:
- 可以支持海量的 key-value 映射;
- key 的类型可以是字符串、整数等类型(
void *);value 可以是复杂的数据类型(string, hash, list, set, sorted set)或者是整数、浮点数等; - 为了避免哈希冲突,采用了链地址法,将冲突的 Entry 串联了起来;
- 为了避免在进行扩容或者缩容时,需要对海量 keys 进行 rehash 而导致阻塞时间过久,采用了渐进式 rehash 策略;
- 提供了安全和非安全的迭代器,方便对整个字典进行迭代;
- 对于 keys 非常大的字典,提供了
dictScan方法,间断迭代,避免因为普通迭代时阻塞其它操作。
数据结构
1 | typedef struct dictEntry { |
字典整体结构可以用下图来表示: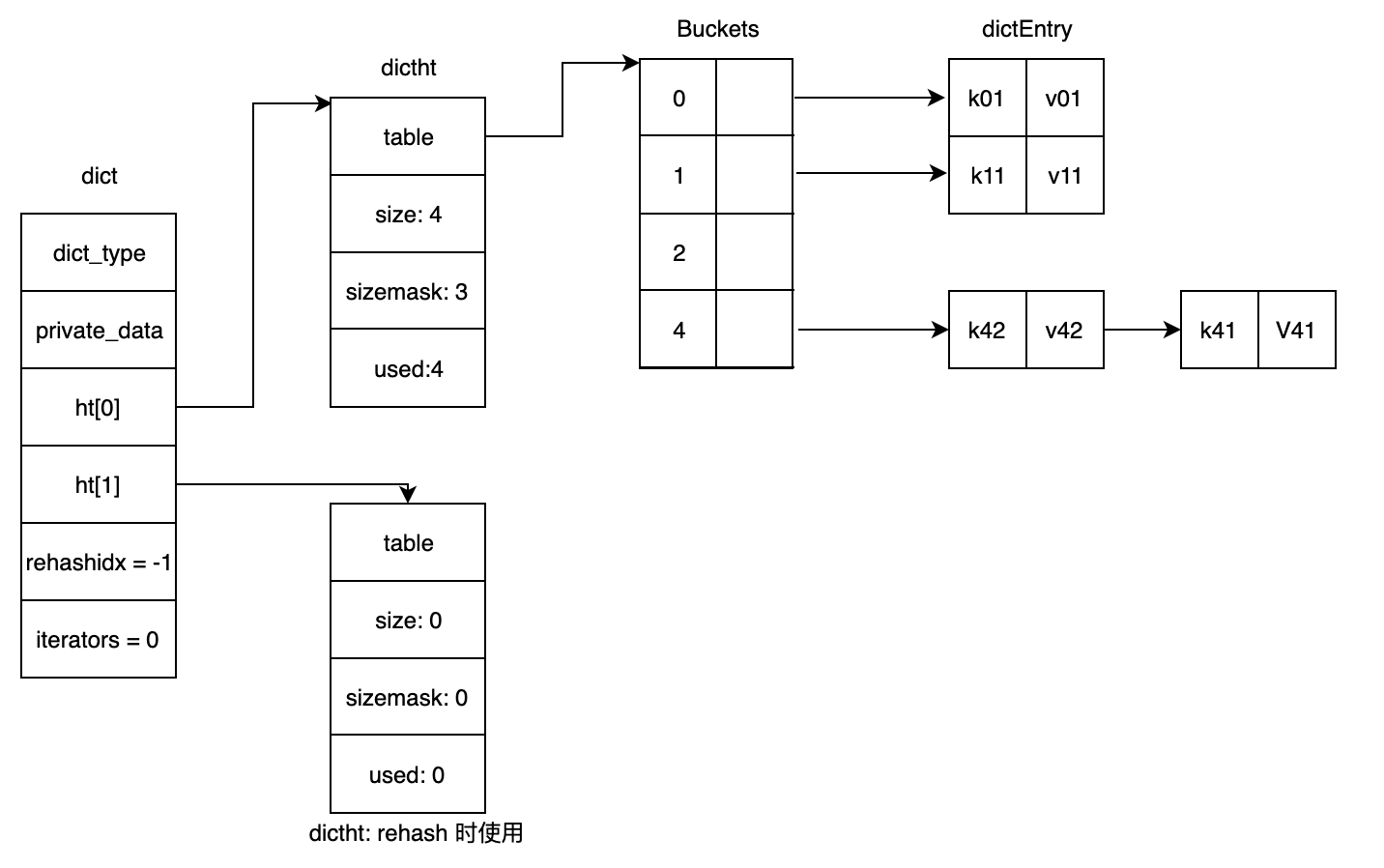
扩容与缩容
在执行 dictAddRaw() 时,会尝试进行扩容,调用流程如下:
1 | dictAddRaw() |
所以扩容或者缩容的核心逻辑在 dictExpand() 函数,我们来看看该函数实现:
1 | int dictExpand(dict *d, unsigned long size) |
在需要的时候,Redis 可以对字典执行缩容操作,具体可以调用 dictResize() 函数实现:
1 | int dictResize(dict *d) |
渐进式 Rehash
为了避免在 rehash 期间,因为要迁移的 keys 太多,导致阻塞其它操作时间太久,Redis 的字典实现中,使用了渐进式 rehash 的策略,从而将对大量 keys 的迁移分散在 N 次操作中,直到最终完成,具体实现参见 dictRehash()。
采用了渐进式 rehash 策略后,每次在执行查找、插入、更新、删除以及 Redis 服务器空闲时,可以执行一部分 keys 的 rehash 操作。具体执行时机如下:
_dictRehashStep() -> dictRehash(d, 1):dictAddRaw()dictDelete()dictUnlink()dictFind()dictGetRandomKey()dictGetSomeKeys()
incrementallyRehash() -> dictRehashMilliseconds(d, 1) -> dictRehash(d, 100):Server 处于空闲时执行 1ms 的 rehash 工作。
普通迭代器与安全迭代器
迭代器是一种常见的设计模式,它可以方便我们对容器中的元素进行遍历,但不需要了解容器内部实现细节。Redis 的字典也我们提供了迭代器数据结构,其定义如下:
1 | typedef struct dictIterator { |
安全迭代器和普通迭代器的区别:
- 安全迭代器允许我们在迭代期间,执行查找、删除、新增等对 dict 有副作用的操作(如执行
keys *命令时会创建安全迭代器); - 普通迭代器则只能允许我们执行
dictNext()进行迭代,其它操作是不允许的(如执行sort会创建非安全迭代器)。
那么,为什么会有这样的限制呢?这主要是因为在迭代期间,如果有执行查找、添加、删除等操作,可能会发生 rehash,进而导致扫描到重复的 entry。
普通迭代器在迭代开始时,计算出当前 dict 的指纹,并在迭代结束时再次计算 dict 的指纹,从而确定 dict 在此期间是否发生过修改过,相关实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25dictEntry *dictNext(dictIterator *iter) {
while (1) {
if (iter->entry == NULL) {
dictht *ht = &iter->d->ht[iter->table];
if (iter->index == -1 && iter->table == 0) {
// 开始迭代,计算下 fp
iter->fingerprint = dictFingerprint(iter->d);
}
iter->index++;
// ...
}
// ...
}
return NULL;
}
void dictReleaseIterator(dictIterator *iter) {
if (!(iter->index == -1 && iter->table == 0)) {
if (iter->safe)
iter->d->iterators--;
else
assert(iter->fingerprint == dictFingerprint(iter->d));
}
zfree(iter);
}
那么,安全迭代器又是如何做到安全的呢?其实策略很简单,就是在执行对 dict 有副作用的操作时,阻止其进行 rehash 即可,这样可以保证底层的 hash tables 不会有 keys 的迁移。具体实现如下:
- 迭代器初始化时,
safe字段置 1; - 初次迭代时,执行
iter->d->iterators++,告诉dict当前存在安全的迭代器在运行; _dictRehashStep时,如果dict->iterators != 0则不会执行 rehash。
间断迭代器
为了避免扫描所有的 keys 而造成长时间的阻塞(事实上,我们的生产环境是禁用 keys 命令的),Redis 在 2.8 之后加入了 scan 操作,从而能够间断地迭代整个字典。zscan 和 hscan 底层都会执行间断迭代操作,它的具体实现参见 dictScan,核心是围绕一个游标进行的,关于它的具体策略可以参见源码的详细描述。
这里总结下 dictScan 算法的主要特点:
- 迭代器本身是无状态的(和上面的两个相比),迭代位置是基于游标计算的,而游标会返回给用户,由用户保存,并在迭代时传入;
- 可能会迭代到重复的元素,但由于采用了 reverse binary iteration 算法,能够保证不漏遍历且尽可能不重复遍历;
- 每次迭代会返回多个元素,这主要是因为避免 rehash 的影响,每次会将一个 bucket 上所有的 keys 都返回出去。
整数集合(intset)
顾名思义,intset 是转门用于存储整数的集合。它实际上也是为了节约内存而设计的,随着元素中最大的元素的类型发生变化,它也会按需扩容。intset 还有个特点是有序且不重复(可以想到查找时就可以光明正大地利用二分算法了)。
intset 实际上是 Redis 集合类型底层使用的数据结构之一,当元素为 64 位以内有符号整数(支持 int16_t, int32_t, int64_t),且元素个数不多(取决于 set_max_intset_entries 设置)时使用。当元素个数超出设定值,或者新增元素类型非整数,intset 就会被转换成 hashtable,也就是使用 dict 来存储。具体可以看下面的代码:
1 | robj *setTypeCreate(sds value) { |
数据结构
1 | typedef struct intset { |
简单画了个内存布局图如下,相信可以直观地表达这个数据结构的特点:
核心源码
intset 的核心 API 比较少,且实现比较简单,很容易看懂,所以在这里不多赘述了,相关源码中文注释直接看 这里。
1 | intset *intsetNew(void); |
快速链表(quicklist)
快速链表(quicklist)本质上也是一个双向链表,但是它的每个节点存储的元素位于 ziplist 中,并且中间节点的 ziplist 还可以使用 LZF 算法进行压缩,进一步节省内存。总的来说,quicklist 是一个综合了双向链表和 ziplist 优点的数据结构。ziplist 最大的特点是节约内存,但不适宜存储过多的元素;而链表则便于从头部或者尾部执行插入或查找。
因此,quicklist 算是为 Redis 列表类型 t_list 特别定制的数据结构,兼顾了时间和空间效率。我们通常使用的 LPUSH, LPOP, RPUSH, RPOP 命令,实际上只需要操作列表两端即可,而 qucklist 恰好维护了 head 和 tail 的节点指针,方便快速定位。
数据结构
1 | // quicklist 是对快速链表这种数据结构的抽象,其中存储了一些元信息。 |
通过下图可以对 quicklist 有个直观的感受,便于理解这种数据结构:
核心源码
quicklist 的源码比较多,就不再本文中赘述了,详细的源码注释可以在 此处 查看。值得重点关注的几个函数如下:
1 | // n 为 quicklist 节点个数,m 表示内部 ziplist 的元素个数 |
总结
这里就不多废话了,对于基本的数据结构做了点总结,放在下面的思维导图中。其中 APIs 分支并非每个数据结构全部的接口,而是一些比较有趣,值得阅读源码的接口,有兴趣地话可以欣赏下它们的内部实现。如果有任何问题,欢迎留言指正~