引言
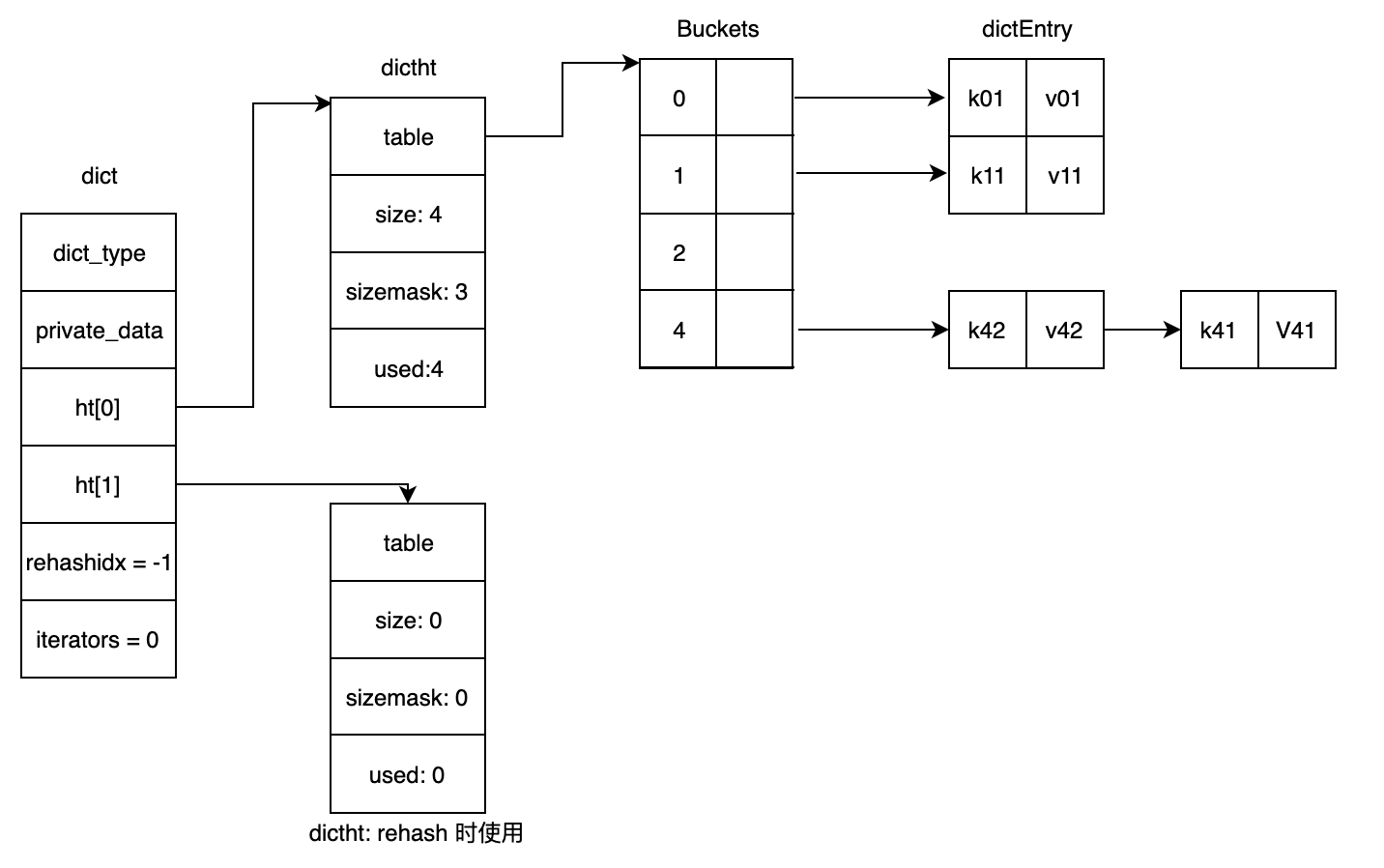
字典在 Redis 中是一个非常重要的数据结构,因为 Redis 本身就是一个键值数据库。我们先来回顾下在 Redis 源码学习之基本数据结构 中提到的 Redis 字典实现的一些特点:
- 支持海量
<key, value>存储; - 使用渐进式 Rehash 策略,避免因为需要迁移的 buckets 太多导致阻塞时间过久(Redis 核心处理逻辑是单线程模型);
- 默认使用 SipHash 算法计算键的 hash 值;
- 对于哈希冲突问题,采用了常见的链地址法,且新加入的节点会插入到链表的头部;
- 字典内部维护了两张哈希表,其中第二个哈希表会在扩容期间(Rehash)使用;
- 提供了安全和非安全的迭代器,方便对整个字典进行迭代。
在看了 Redis 字典源码,搞懂它的工作原理后,有没有想要自己实现下呢?所以,本文将介绍如何使用 Go 语言来山寨一个 Redis 字典实现,虽然「容貌」有异,但「内核」还是基本一致的。为了简单起见,我们在实现的时候先不考虑 goroutine 安全问题,焦点放在 Redis 字典实现的核心思想上。所以后面的实现,都假设只有一个 goroutine 在对字典进行操作。由于 Go 语言自带 GC,所以使用它来实现就不用烦心内存管理的问题了(在 Redis dict.c 实现中,还有很多代码是涉及内存申请和释放的),这样就能让我们更加容易地理解核心的实现策略。
一点说明
正所谓「入乡随俗」嘛,所以在使用 Go 语言实现的字典中,并没有照搬原先 Redis 中字典的接口,而是提供了一组类似于标准库 sync.Map 的接口。
另外,什么样的 key 可以作为字典的键呢?首先,必须要是方便计算哈希值的;其次,方便进行直接比较。我们知道在 Redis 的字典实现中提供了一组接口,供实际使用字典存储的数据类型实现。之所以这样做,也是为了更好的扩展性。
1 | typedef struct dictType { |
不过为了简单起见,在使用 Go 语言实现时字典时,传入的 key 和 value 均为 interface{} 类型,并没有强制的接口实现要求。另外,针对 key 将只支持 string 和 int 类型及其变种。这种可以满足基本的使用场景,同时也能够拥有和 sync.Map 一样的接口签名。
最后,来看下字典的接口设计:
1 | // Store 向字典中添加新的 key-value |
实现细节
数据结构
1 | type Dict struct { |
字典初始化
1 | // New 实例化一个字典。 |
在哈希表中查找指定的键
下面这个函数将基于指定的 key 计算出对应的 hash 值(使用 SipHash 算法,Redis 字典中默认使用的哈希算法),并且通过查询哈希表来确定对应的 key 是否存在于字典中。这个函数比较重要,在后面的 Load 和 Store 函数中都有应用,下面来看看它的具体实现吧:
1 | // keyIndex 基于指定的 key 获得对应的 bucket 索引 |
查询键值对
1 | // Load 从字典中加载指定的 key 对应的值。 |
存储键值对
1 | // Store 向字典中添加 key-value。 |
删除键值对
删除操作值得一提的是,在查找到要删除的 Entry 后,需要记得调整哈希桶的头指针,可能被删除的 Entry 恰好就是头节点。代码实现比较简单,如下:
1 | // Delete 从字典中删除指定的 key,如果 key 不存在,则什么也 |
扩容和缩容
在给字典添加键值对时,会调用 loadOrStore 方法,而在该方法内部调用了一次 d.expandIfNeeded() 方法尝试给字典按需扩容。那么,字典扩容的时机是什么呢?扩容的策略又是怎样的呢?且看源码:
1 | const ( |
我们知道了扩容是何时进行的了, 但是看起来并没有在删除元素时执行缩容操作呢?那缩容会在什么时候执行呢?在 Redis 中,是由字典的使用者来确定缩容的时机的,比如在删除键值对后,或者在 serverCron 中执行(具体调用链路为:serverCron->databasesCron->tryResizeHashTables->dictResize)。该方法的实现很简单,用 Go 语言表达如下:
1 | // Resize 让字典扩容或者缩容到一定大小。 |
渐进式 rehash
渐进式 Rehash 的思想很简单,就是将大量的工作分成很多步完成。在上面的源码中可以看到,Load, Store, Delete 方法中,都有调用 d.rehashStep(),进而又会调用 d.rehash(1)。下面我们来看看渐进式 Rehash 是怎么实现的:
1 | // rehash 实现渐进式 Rehash 策略。基本思想就是,每次对最多 |
字典迭代器
迭代器的数据结构定义如下:
1 | // iterator 实现了一个对字典的迭代器。 |
在 Redis 的字典中,提供了两种类型的迭代器,分别通过 dictGetIterator 和 dictGetSafeIterator 获得。普通迭代器只能执行和字典关联的 dictNext 方法,不允许执行 dictFind,dictAdd 等操作,这主要是因为这些操作可能会引起 Rehash,从而导致在迭代期间可能会扫描到重复的键值对(比如在执行 Rehash 期间,某些键值对被迁移到了新的哈希表,但是我们是优先扫描第一个哈希表,然后再扫描第二个哈希表,而此时可能会遇到之前扫描过的元素)。当然,Redis 的普通迭代器是没法阻止你在迭代期间执行不安全的操作的,但是它会通过计算迭代前后字典的指纹信息,并在最后进行比对,若指纹不匹配,则无法通过 assert(iter->fingerprint == dictFingerprint(iter->d)) 断言。
那么安全迭代器又是如何做到可以允许 dictFind 和 dictAdd 等操作执行的呢?其实它是通过阻止字典 rehash 实现的,正因为如此,它才可以放心大胆地扫描哈希表中的 Entries,而不用担心遇到重复的 Entries。在上面的代码中可以看到,在 Load、Store 和 Delete 中都有直接或间接地调用 d.rehashStep() 方法,它的实现如下:
1 | func (d *Dict) rehashStep() { |
最后,我们来看看迭代器最重要的 next() 方法实现,就可以看到安全迭代器和普通迭代器的区别了:
1 | // next 会依次扫描字典中哈希表的所有 buckets,并将其中的 entry 一一返回。 |
使用示例
1 | func main() { |
总结
好啦,关于 Redis 字典的实现介绍就到此为止啦。相信看完上面的代码后,应该可以了解到 Redis 字典的扩容机制、渐进式 Rehash 策略,以及哈希冲突解决方案。完整的实现代码及其单元测试参见 go-redis-dict。