引言
应求开发一个简单的爬虫,用于从快递 100 抓取快递网点的分布,输入省份+城市+区县,然后是快递公司名称,抓取其对应的快递网点的信息(包括名称、地址、电话、坐标等)。说起来,开发这样一个简单的爬虫其实没什么难度,也没什么技术含量(没有时间要求、不需要分布式抓取、没什么反反爬策略加持等),不过这期间也遇到一些比较有趣的问题,特此记录下。
另外就是第一次接触了 pyecharts 这个数据可视化工具,用起来还挺方便的。样式配置好,还是会带来很好的视觉冲击的!当然,关键是利用这种工具有助于增加对抓取数据的理解(看具体需要的分析维度了)。
整个过程还是挺有趣的,虽然定位某些元素的时候很麻烦,写 XPath 表达式也比较枯燥(不要指望浏览器自动生成的 XPath,通常都不够通用)。但是完成整个任务后,还是有些收获的。下面开始吧~
确定方案
尝试 API 直接获取
快递 100 对外公开的 API 文档在此,但是并没有开放网点查询的接口,故无法使用。直接通过 API 查询是最省心的方式,但是目前这条路行不通。
尝试分析网页请求,间接使用 API 请求
网点查询的主页,可以根据选择的城市和快递公司,页面内容自动切换。此时,还是尝试分析其 API 请求,因为这个通常是抓取网站最简单的方式。
打开 Chrome 浏览器的调试模式,通过点击页面上的筛选项,查看网络请求,确定请求了什么接口,传递的参数是什么,返回的参数是什么,从而能够模拟其请求方式来获取数据。接下来演示的是查询上海地区的某快递公司的网点。
截图 1:请求方式为 POST,URL 为 www.kuaidi100.com/network/searchapi.do
截图 2:以表单的形式,提交了请求的参数,也就是页面点击的筛选项。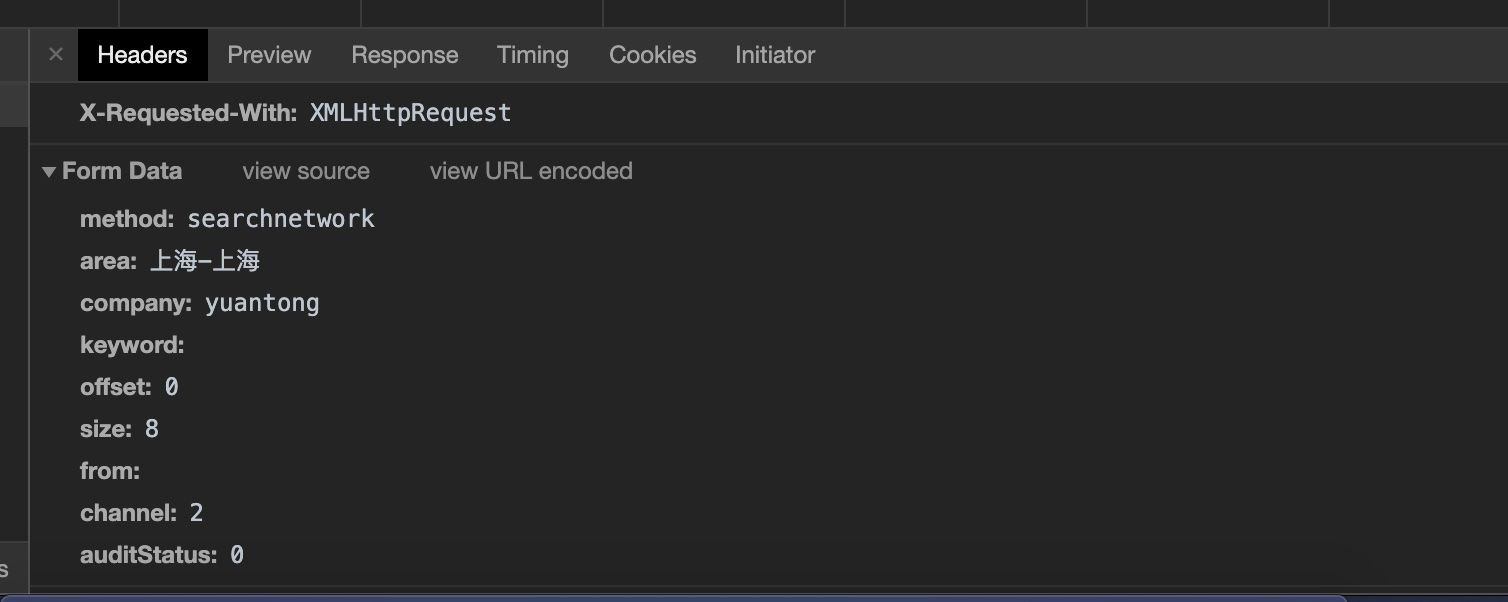
截图 3:当完成请求后,可以看到其返回结果为 JSON 结构,其中的 netList 正是想要找的网点数据。
尝试分析网页结构,采用传统的方式抓取
一般在进行网站数据抓取时,能通过其 API 获取,就尽可能去利用。使用 API 请求数据的好处有这么几点:
- 省去了分析网页 HTML 结构的时间,可以直接解析接口返回的数据,提取想要的信息并存储即可;
- API 请求方式最为简单可靠灵活,且能适应较高的抓取频率;
- 相对于分析网页 HTML 结构,提取信息的方式,API 抓取通常不用像担心前端页面频繁改版而导致爬虫程序也要即使更新的困境,方便维护。
不过只是通过 API 来抓取,感觉不是很有趣,在 Selenium 的帮助下,以可视化的方式抓取页面貌似更有趣点。这里的思路如下:
- 安装 Selenium + Chrome Web Driver,通过操纵浏览器模拟人类访问页面的方式来抓取数据;
- 编写爬虫程序,控制浏览器打开网点查询的首页:https://www.kuaidi100.com/network/
- 接收输入的城市和快递公司名称作为参数,然后操纵浏览器点击下拉框,选择城市;然后操纵浏览器点击指定的快递公司;
- 接下来开始解析页面结构,提取快递网点数据转换为 JSON 格式(地理位置坐标通过百度地图 API 获得),存储在指定路径下;然后不断控制浏览器翻页,完成剩余页面解析,至此对应的网点信息抓取完成。
准备开发环境
- Python 3.7 环境;
- selenium-python,其使用文档参考此处;
- chromedriver 下载,并解压得到可执行文件;
- Anaconda 环境安装,并且需要保证 Jupter Notebook 能够正常工作;
- 依赖的重要 Python 包安装:
- pyecharts
- echarts-countries-pypkg
- echarts-china-provinces-pypkg
- echarts-china-cities-pypkg
- echarts-china-counties-pypkg
- echarts-china-misc-pypkg
- requests
- 记得安装 Chrome 浏览器。
页面关键元素定位
根据上述抓取思路,需要做的是定位一些关键元素,并且能够从 HTML 中抽取出需要的信息。页面元素定位,需要了解下 XPath 语法,摘取想要的元素。
小技巧,可以在 Chrome 控制台通过 $x('xpath-expression') 验证选择器是否正常: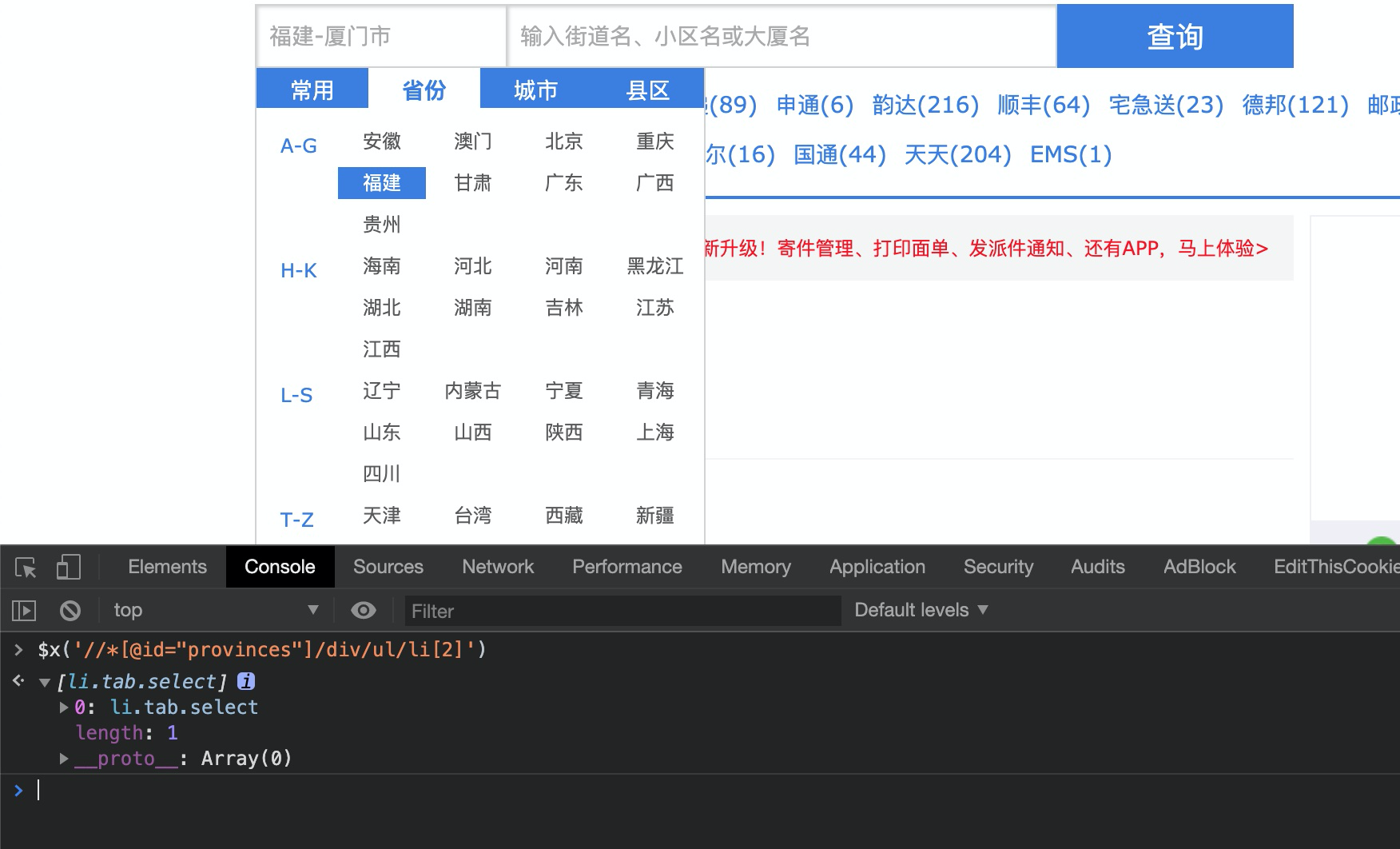
省份选择下拉框元素 id 为
provinceSelect:
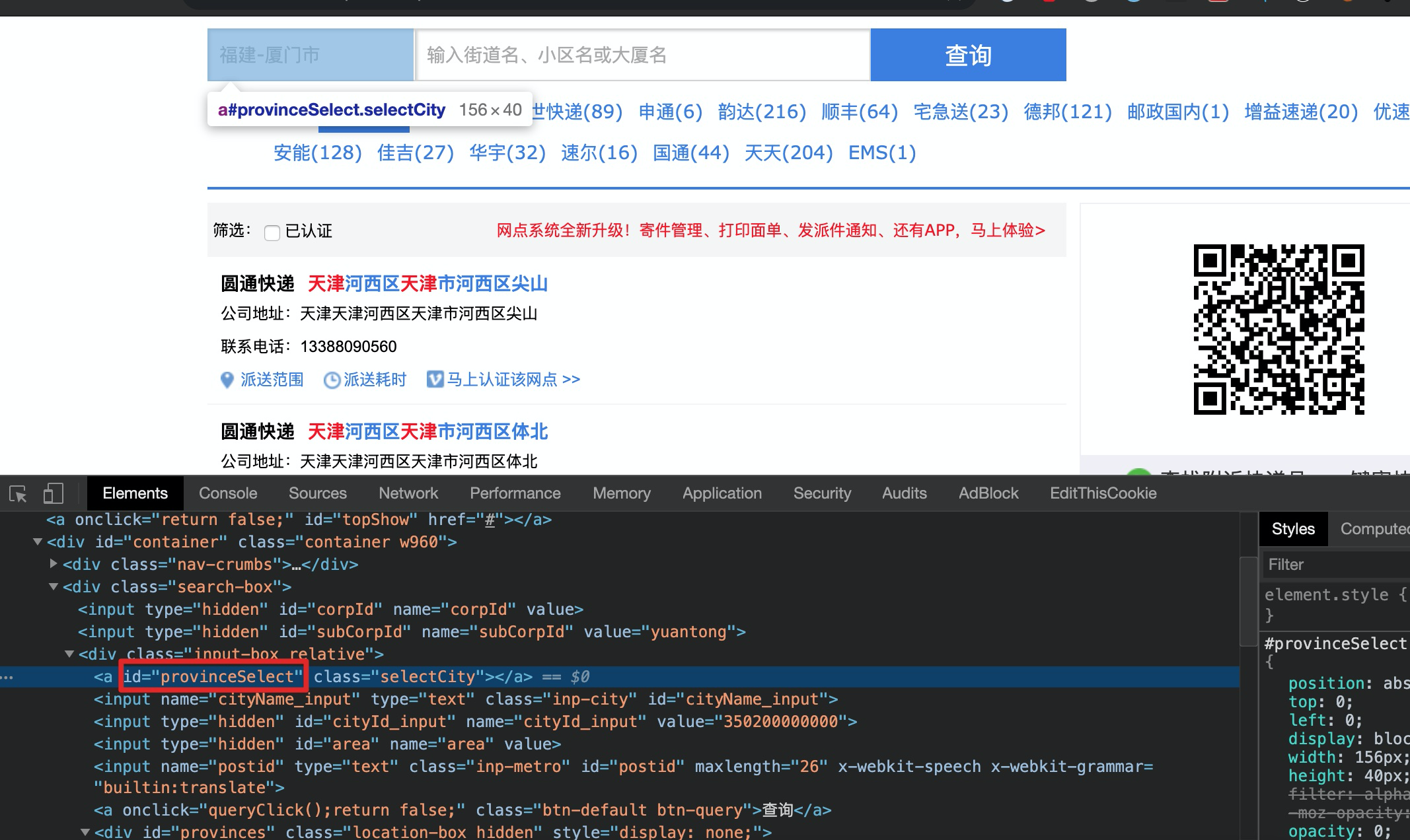
定位省份位置(拷贝其 XPATH)
小结
其它关键元素确定方式类似,主要以 XPath 的方式查找。得到最终需要的 XPath 表达式如下:
1 | class XPathExpression: |
写代码
main 函数是关键入口,它会调用爬虫类搜索指定位置指定公司的快递网点信息,并将返回的数据存储到指定的路径下,使用 json line 格式(即每一行都是 json 格式字符串)存储。
1 | def main(province, city, provider='全部'): |
核心爬虫类
1 | class DeliveryNetworkSpider(object): |
坐标查询
1 | BASE_API = 'http://api.map.baidu.com' |
控制抓取数据
比如,下面就是抓取中通快递在北京各个地区的网点。启动后,会通过 Selenuium 控制 Chrome 浏览器访问查询网站,并点击对应的元素,完成数据的抓取。
1 | main(province='北京', city='北京', provider='中通') |
整个工作过程演示参见 百度网盘(提取码: kaun)。抓取到的数据示例如下:
绘制简单的热点地图
这里就需要使用关键的 pyecharts 了,具体怎么安装和配置就不多说了,它有非常完善的中文文档,以及一些 Demo 可以学习。以下就是利用上述抓到的数据,做个简单的演示,看看这些快递网点的具体分布热点是怎么样的。
我们需要切换到爬虫目录下,并启动 Jupter Notebook:
1 | cd path/to/kuaidi100/src |
紧接着,选择 src/heatmap.ipynb 文件打开: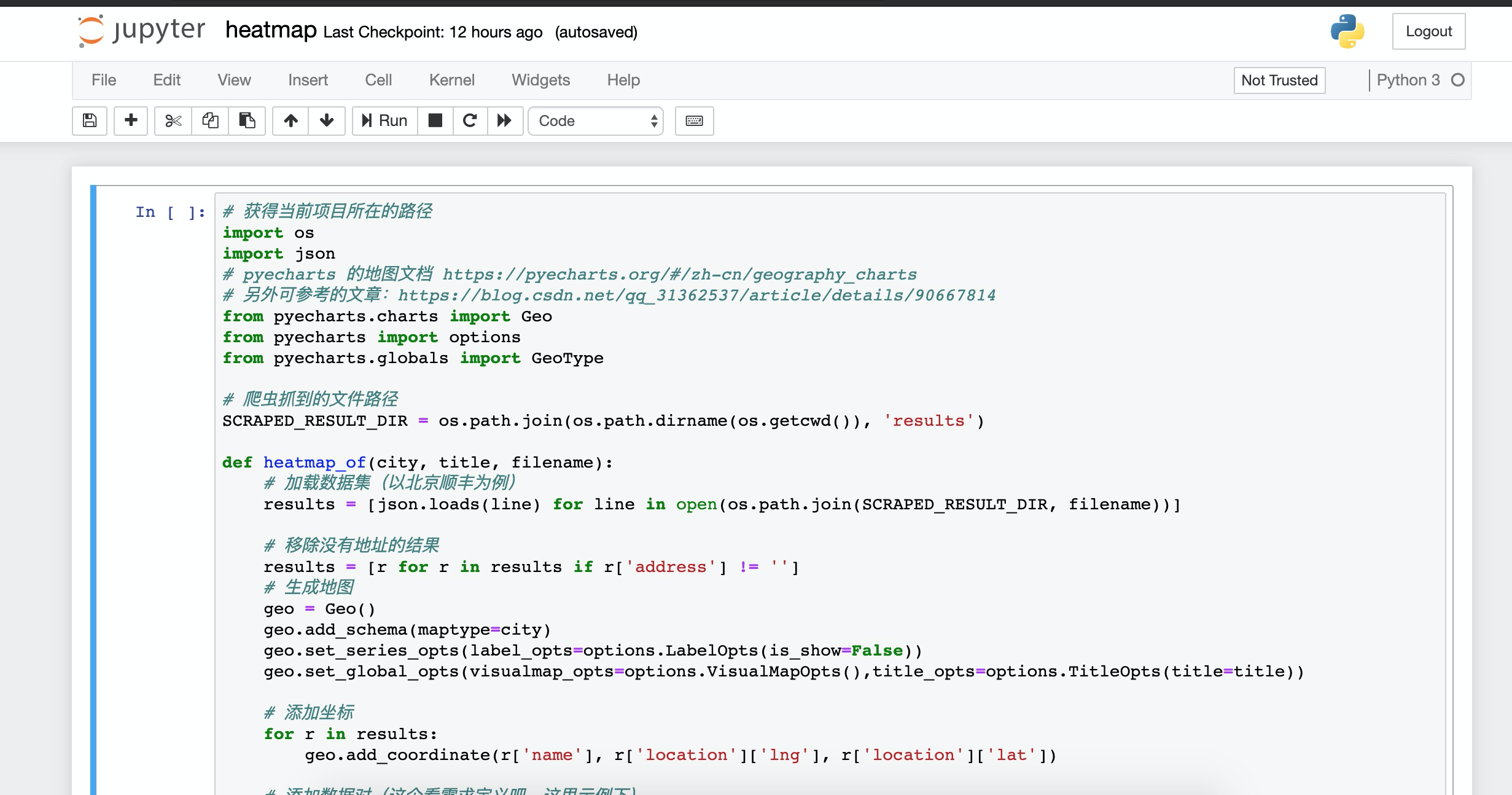
菜单栏 Cell->Run All 执行所有代码,可以看到简单的热点地图如下所示: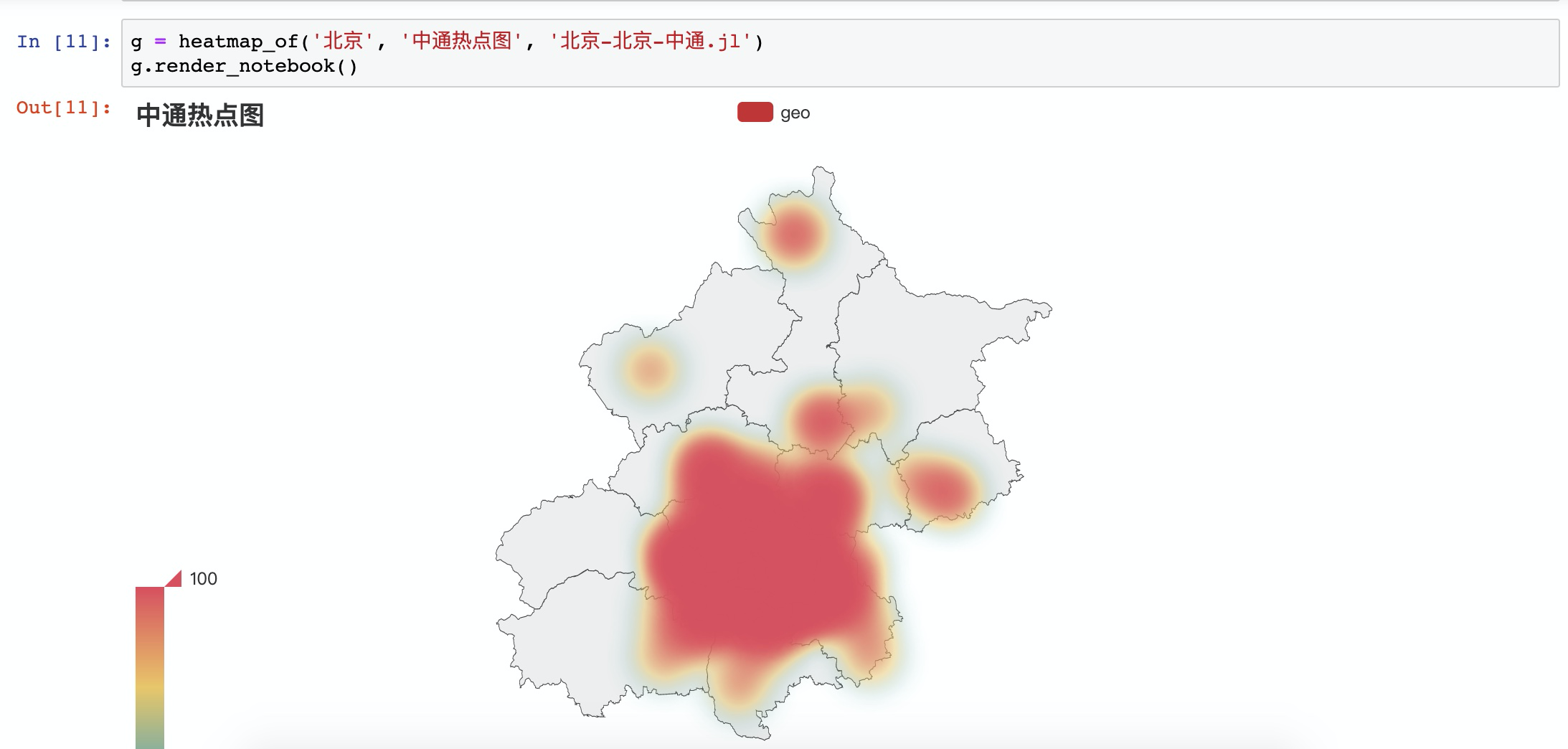
总结
至此,整个折腾的过程就完结咯。主要时间花费在确定爬重的方案,以及使用灵活的方式定位元素上。在实际测试中,也遇到一些小问题,并做了部分优化:
- 比如某些情况下元素
click会失败,这时为了保证爬虫的健壮性,需要做异常捕获;页面加载未完成时,可能无法查找到指定元素,导致爬虫程序挂了,这里就需要配置 Selenium 隐式等待 10s。 - 为了方便观察 Selenium 正在操纵的元素,这里借助了
driver.execute_script()的方式给选中的元素添加红色边框。 - 另外,考虑到爬取频率过快,可能导致触发反爬策略,这里简单做了延迟等待(
time.sleep())。
整体而言,写得比较简单,所以这里也就简单记录下。完整的代码仓库参见:kuaidi100-spider。