引言
随着移动互联网、物联网、云计算以及未来 5G 技术场景的应用拓展,相关应用的数据规模也在不断增长,面临的存储压力越发明显。在此背景下,传统的单机 MySQL 数据库已经无法轻松应付,即便以分库分表的方式应对,也依然存在扩展性较差、可伸缩能力不足、自动化运维能力不足等问题。伴随着 Google 内部的分布式数据库 Spanner 和 F1 的设计思想开放,PingCAP 公司在 2015 年受到相应的启发后开发了 TiDB 数据库,历经将近五年的迭代,目前它已经成为开源社区非常知名的 NewSQL 数据库代表了,并且已经在诸多知名企业中得到了部署和应用。
在正式引入 PingCAP Talent Plan 系列课程介绍前,有必要对 TiDB 有所了解。以下将要介绍的内容包括:
- TiDB 是什么?
- TiDB 的核心组件有哪些?
- 为什么会诞生 Talent Plan 课程?
- Talent Plan 课程内容是什么?
初识 TiDB
从官网上得知,TiDB 是一款真正意义上的分布式关系型数据库,并且高度兼容 MySQL 协议,这也为我们迁移广泛基于 MySQL 的应用奠定了基础。下面来看看它主要有哪些特性呢?
- 支持 OLTP + OLAP 的混合场景,是一款 HTAP(Hybrid Transactional/Analytical Processing) 融合型数据库产品;
- 支持分布式事务(乐观事务+悲观事务模型均支持);
- 高可用,具备故障自动恢复能力;
- 易于伸缩,TiDB 和 TiKV 均可水平扩展,支持海量数据存储;
- TiDB 4.0 全面拥抱云原生,提供了非常多的部署方式,同时为了方便本地部署测试,tiup 工具的诞生,也为像笔者这样的小白用户铺平了道路。
核心组件

TiDB in Action 中对于 TiDB 的整体架构有详细的描述。概括来说,TiDB 的整体架构清晰易懂,包括三个核心组件:
- TiDB:此为 SQL 层,即无状态计算层。负责 SQL 解析、优化,并生成分布式执行计划。实际的数据请求会发送给底层的存储引擎 TiKV。具体可以阅读 谈计算 了解更多细节。
- TiKV:此为存储引擎层,本身是一个支持分布式事务的 KV 数据库。TiFlash 是列式存储引擎,主要是针对分析型场景查询而设计。 具体可以阅读 说存储 和 TiFlash 架构原理 了解更多细节。
- PD:全称为 Placement Driver,它负责整个 TiDB 集群的元信息管理、存储节点访问自动负载均衡调度、分布式事务 ID 分配等,可以看成整个集群的大脑。可以阅读 讲调度 了解更多细节。
更多学习资源
TiDB 的社区资源相当丰富,在 PingCAP 官网中可以看到很多学习资源,笔者简单整理了下,传送门如下:
跃跃欲试
如果对于分布式系统,尤其是分布式存储系统感兴趣的话,那么跟着 PingCAP 推出的系列课程学习并参与到开源项目中,一定会有很多收获。不过面对如此庞大的系统,想要深入了解其原理并能够读懂源码还是有些门槛的。好在有很多官方的源码解读博客可以学习~
不过在实际学习中还是遇到一些困难,比如编程语言(Go 和 Rust)实践不足,分布式系统理论和实践结合存在鸿沟等。所以,PingCAP 官方推出了 Talent Plan 课程,分为 TiDB 方向和 TiKV 方向。由于笔者对于 Rust 语言的了解仅仅浮于表面,实践不多,刚好 Talent Plan 提供了这样的机会,可以从 0 到 1 设计并实现一个分布式存储系统。在完成这个系列课程学习后,也能让我们更好地理解 TiDB 和 TiKV,并且在尝试阅读它们的源码时,也不至于一头雾水啦~
在 GitHub talent-plan 仓库中可以看到关于这个系列课程的介绍。为了便于快速了解课程大纲,画了一个思维导图如下(笔者主要关注的是 Rust 部分):
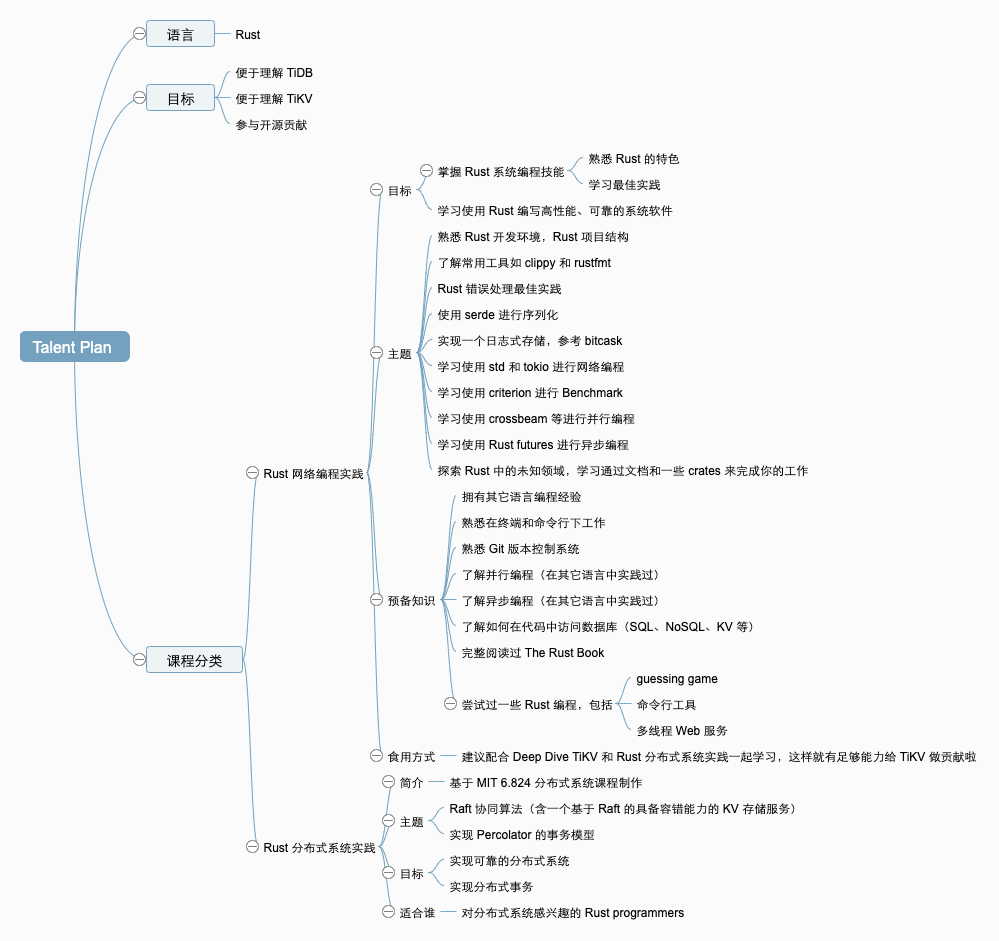
上车,走吧
接下来,笔者将按照 Talent Plan 安排的课程循序渐进地学习,并在学习中做一些笔记,以便随时复习,欢迎围观交流~