引言
惭愧,时隔两个月继续本系列课程的学习,之前因为一些工作上的事情耽搁了很久。本节课程的学习素材非常丰富,也有很多是我们在编写 key-value 数据库前需要掌握的思想。
在资料学习部分,我们首先需要了解下什么是日志结构存储(Log structured storage),接下来需要掌握在 Rust 中如何以优雅的方式处理错误,最后还需要学习下 std::collections 中的一些数据结构和 std::io 中的常用函数。
在练习题部分,我们还将接触 Rust 中特别常用的序列化和反序列化框架 serde,并使用该框架完成 json, ron 和 bson 相关的练习,掌握它的基本用法。
材料阅读
日志结构存储技术简介
Damn Cool Algorithms: Log structured storage 对于日志结构存储(Log-Structured Storage,以下简称 LSS)技术的基本原理做了简要介绍,我们把作者讲解的知识点进行了梳理,仅供参考。
当我们要设计类似文件系统、数据库等存储系统时,我们的主要目标当然是要将数据存储到磁盘上。此时,我们会面临这么几个问题:
- 为新的记录分配存储空间;
- 存储和更新索引数据;
- 当需要扩展已有的存储对象时,需要考虑碎片化的问题(当新的对象替换旧的对象存储空间时)。
LSS 就是用来解决上述问题的技术之一,早期它被尝试应用在文件系统中,不过因为存在一些缺陷,而没有得到广泛使用。但是在数据库存储引擎领域,这种结构化存储技术却得到了越来越多的青睐,因为相对于在文件系统中的应用,在数据库存储引擎领域,使用 LSS 技术面临的问题更少,并且还带来了很多优势,让存储管理变得更加简单。
简单来说,日志结构存储系统可以看成是一系列仅追加(append only)的数据条目(data entries)。所以,当需要写入新的数据时,只需要追加的日志结尾,而不需要查找到具体的写入位置,这样可以大大提高写入吞吐量。在写入记录的同时,也会更新索引数据(metadata)。索引数据也是追加到日志结尾的。
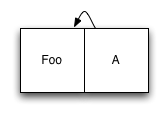
我们接下来看一个简单的例子(假设日志中仅包含一条数据,以及一个引用该数据的索引节点(index node)):
接下来我们新增一个元素到日志结尾,然后更新下索引条目,并将更新后的版本追加至日志结尾:
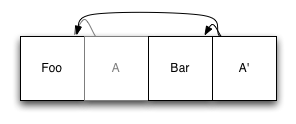
可以看到,原有的索引条目(A)还在日志文件中,不过不能使用了,因为我们现在要使用 A’ 来指向原有的数据条目了。
那我们怎么读取文件系统呢?首先,我们需要查找到索引的根节点,最笨的办法自然是读取日志文件的最后一块。然而,这里是可能有并发读写的问题。这里提供一种方案来避免并发读写的问题:可以在日志文件的开头放一个单独的块,用来存储当前根节点的指针。这样,每当我们更新日志,就更新一下第一个节点,保证永远指向最新的根节点。
好啦,接下来看看怎么更新数据。假设需要更新 Foo 为 Foo':
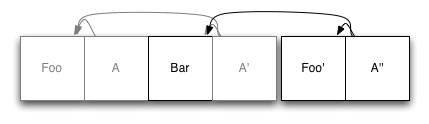
首先我们将 Foo 拷贝到日志的结尾,然后更新索引节点并写入到日志结尾。此时,旧的 Foo 虽然还在日志文件中,但已经没有任何索引引用它了。
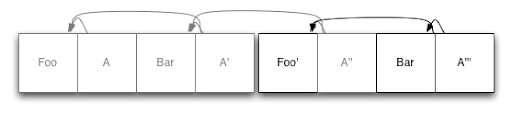
看起来还不错,不过还有一个问题需要关注,那就是空间需要及时释放,否则最终会导致没有可用存储空间了。
这里我们分别考虑文件系统和数据层存储引擎对于存储空间回收方面的问题:
- 对于文件系统:可以将磁盘当作环形缓冲区,这样旧的未被引用的数据可以直接被覆盖,这样可以做到空间复用。不过对于常规的文件系统而言,当磁盘越来越满时,花费在 GC 上的时间就会越多,并且还要将大量数据写入到日志的开头。一旦达到 80% 的磁盘空间使用量,文件系统将因为不堪重负而难以提供服务了。
- 对于数据库引擎:我们可以借助文件系统,将数据库拆分成多个固定长度的分片。当我们需要回收空间时,只需要选择某个分片,将其中活跃的数据写入到新的分片,然后删除旧的分片即可。
接下来我们来梳理下,在数据库引擎中,我们使用 LSS 的优势:
- 无需总是优先删除最旧的段;
- 在何时回收空间上有更多的灵活性;
- 无需传统的 WAL(Write Ahead Log)来恢复数据了,因为此处的日志文件就扮演了这样的角色;
- 关于写入方面的优化,我们可以在内存中维护索引,并定期写入到磁盘。只要我们可以区分完整和非完整事务,我们就可以通过恢复机制完成受损数据的重建;
- 备份更加轻松:只需要连续不断地把已完成的日志段(log segment)拷贝到新的设备中即可;
- 关于并发和事务机制,我们可以使用 MVCC(Multiversion Concurrency Control)机制实现无锁读取;还可以采用乐观事务(Optimistic concurrency)模型提交写操作。
日志结构文件系统设计与实现
LFS 是关于日志结构文件系统的论文。在该文件系统中,日志是仅有的磁盘数据结构,同时包含了索引信息,方便高效读取。作者所在的团队开发了日志结构文件系统原型 Sprite LFS,整体上来说,对于小文件,写入性能是要比那时的 Unix 文件系统快上一个数量级。而在读取和大块写入性能上,和 Unix 文件系统相当或者更好。
在写入场景下,Sprite LFS 能够利用 70% 的磁盘带宽,而 Unix 文件系统只能用到磁盘带宽的 5%~10%。
根据论文的描述,在 Sprite LFS 中,日志是被拆分成多段维护的,并且还有段清理程序压缩高度碎片化段中的有效数据。论文篇幅较长,此处不再赘述,感兴趣的同学可以直接阅读原文。
Bitcask
在说 Bitcask 之前,先来简单认识下 riakkv,它是一个分布式的 NoSQL 数据库。而 Bitcask 则是 riakkv 支持的后端单机 KV 存储引擎之一。此外,它还支持 LevelDB 以及纯内存的 Memory 存储引擎。
Bitcask 是一款高性能、基于日志结构的 Key/Value 存储。
优点
- 读写低延迟。得益于其 write-once, append-only 特性;
- 高吞吐。写操作基本可以打满磁盘带宽,性能非常强悍。主要原因有两点:
- 数据在磁盘上无需有序;
- 采用日志结构存储设计,写入时磁盘移动幅度小;
- 可以处理超出 RAM 容量的数据集。数据访问需要先从内存 Hash 表中找到日志文件偏移,再访问磁盘,即使数据集很大,访问依然高效;
- 只需要单次磁盘 Seek 即可定位数据。在内存的 Hash 表中记录了数据在磁盘上的位置,所以通常我们最多只需要一次磁盘访问即可查找到想要的数据,考虑到文件系统的缓存能力,有时候甚至不需要读盘;
- 查找和写入性能可预测。读取时,只需要读一次内存找到磁盘位置,再读盘至多一次即可找到数据;写入类似,只要找到当前打开文件的末尾即可追加数据;
- 快速、有界的崩溃恢复能力。考虑到日志结构存储的特性,只有最后打开的文件尾部可能有部分写入的情况。恢复操作只需要查看最后几次写入,检查 CRC 确认数据是否一致;
- 备份简单。任何基于磁盘块顺序打包或者拷贝文件的工具都可以用来备份 Bitcask 数据库。
缺点
- 所有的键必须能够放入到内存。
实现细节
每个 Bitcask 实例就是一个目录,任意时刻只能有一个操作系统进程打开 Bitcask,我们可以把这个进程看作「数据库服务器」。任意时刻,目录中只有一个活跃文件可以写入,一旦该文件超过阈值,Bitcask 服务器则会关闭该文件,并新建一个文件继续写入。任何关闭(不管是正常关闭还是因为异常退出而关闭)的文件都是不可改变的(immutable),不可再被写入。
数据记录都是顺序追加到活跃文日志文件中的,不需要额外的磁盘寻道等待时间。每条写入的 Key/Value 条目的格式如下:
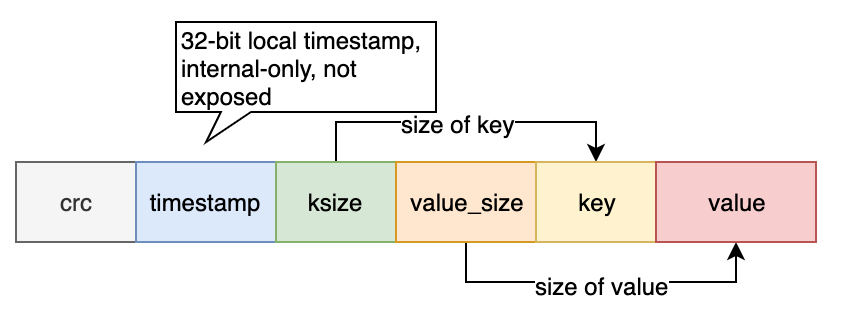
需要注意的是,删除操作只是向日志中写入一个特殊的 tomestone 值,在下次合并时会执行真正的删除操作。直观来看,Bitcask 的数据文件就是一系列记录条目的组合:
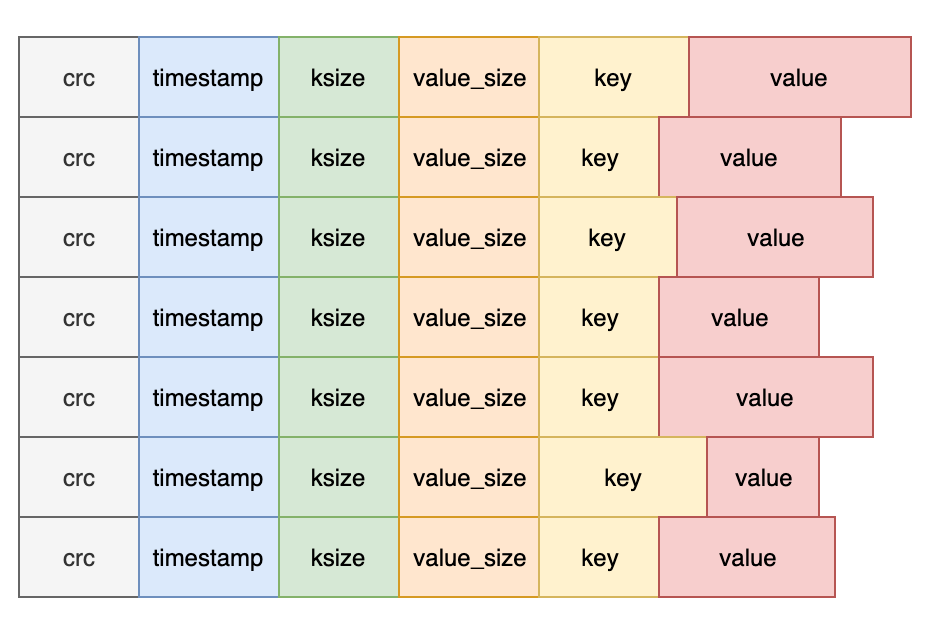
上面简单介绍了记录的格式,删除操作的实现等。但我们怎么能够快速查找记录值呢?答案是,我们需要在内存中维护一个索引结构,在这里叫做 keydir。每当记录追加完成,keydir 就会被更新。简单来说,keydir 就是一个哈希表,其中记录了每个 key 关联的最近写入的 Entry 所属文件、偏移量和值大小数据等,方便快速定位和获取 key 对应的值。
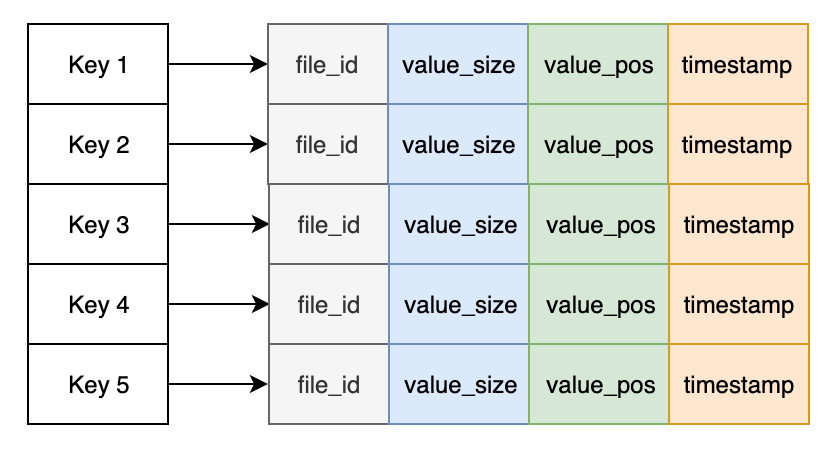
每次写入完成,keydir 都会自动更新,并指向最新的记录位置。而旧的位置虽然保留在磁盘中,但后期会被合并程序自动移除掉,从而回收磁盘空间。
读取 Key 对应的 Value 步骤如下,虽然看起来每次都要读盘,不过考虑到操作系统的文件系统有预加载机制,所以实际读取性能会比预期更好。
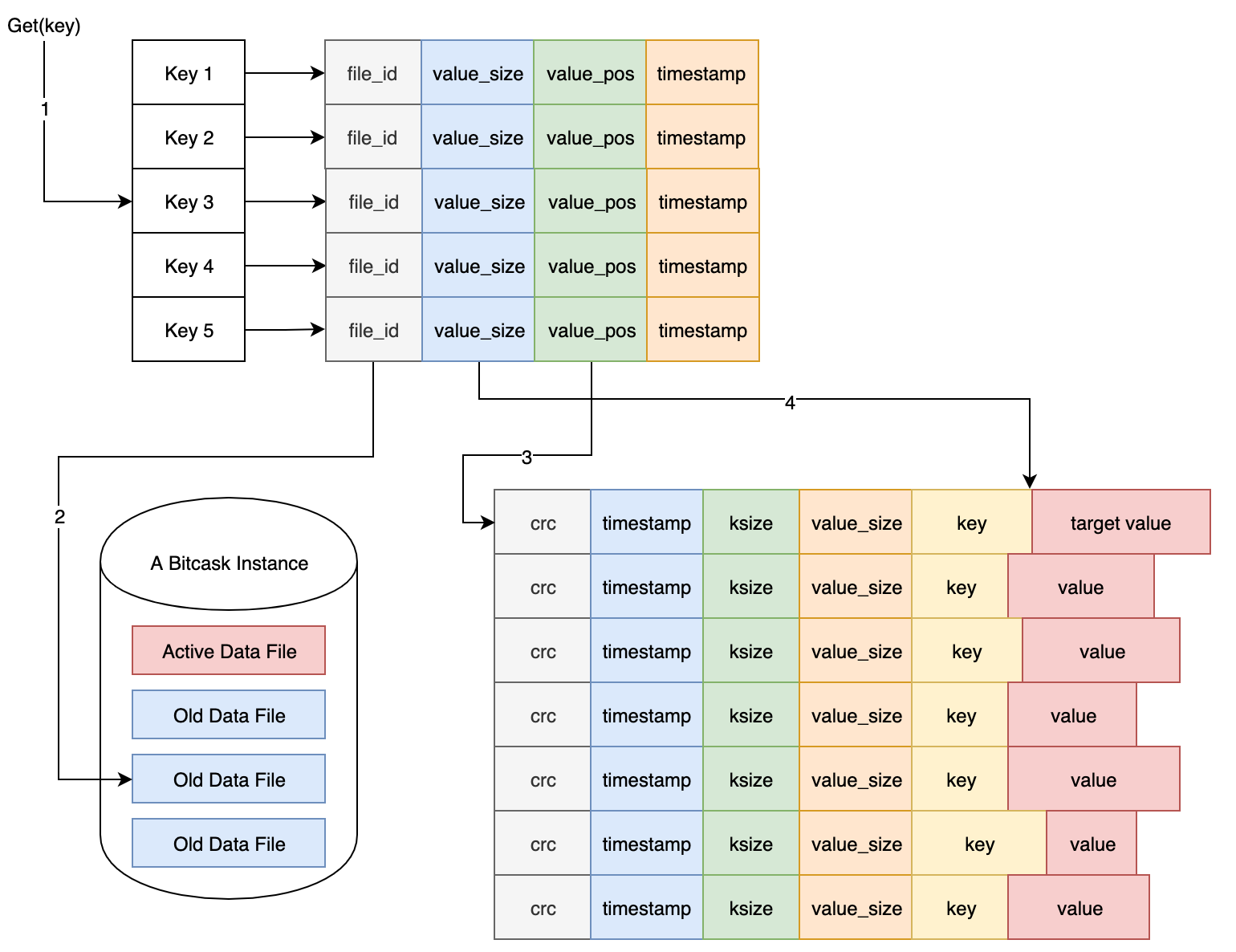
最后,来看看必不可少的合并过程(merging process)。这个后台进程负责遍历所有非活跃的 Bitcask 文件,并输出一系列仅包含当前 Key 对应的最新版本值的数据文件,这样可以释放磁盘空间。
每当合并完成后,还会为数据文件生成相应的 hint 文件,这些 hint 文件包含的是关联数据文件中所有 Key 对应的值的位置、大小等信息。有了这些 hint 文件后,重新启动服务后,可以快速重建 keydir 内存索引,从而大幅度降低服务启动时间。
最后,我们来看 Bitcask 为我们提供的一些 API:
open(DirectoryName, Opts) -> BitCaskHandle | {error, any()}open(DirectoryName) -> BitCaskHandle | {error, any()}get(BitCaskHandle, Key) -> not_found | {ok, Value}put(BitCaskHandle, Key, Value) -> ok | {error, any()}delete(BitCaskHandle, Key) -> ok | {error, any()}list_keys(BitCaskHandle) -> [Key] | {error, any()}fold(BitCaskHandle, Fun, Acc0) -> Acc: 遍历 K/V 对,执行累计操作。其中Fun签名为F(K, V, Acc0) -> Accmerge(DirectoryName) -> ok | {error, any()}sync(BitCaskHandle) - okclose(BitCaskHandle) -> ok
Rust 中的错误处理
错误处理是我们在使用任何语言编写程序时都需要考虑的事情,如果我们没有比较优雅的方式应对错误处理,很有可能导致代码结构不够清晰,降低可读性和可维护性。所以我们学习 Rust,也同样要学习地道的错误处理方式。
Andrew Gallant, Error Handling in Rust 是非常值得阅读的文章,作者提供了非常丰富的示例,循序渐进地引导我们掌握 Rust 中的错误处理方式,并给出了一些经验法则。
当然,笔者也对上述文章进行了翻译,参见 Rust 错误处理,感兴趣的同学可以直接阅读这篇文章。
Rust & Python & Go 错误处理对比 则借助一个小例子,对比了三种语言错误处理的方式,感兴趣的话,也可以阅读~
std::collections 文档学习
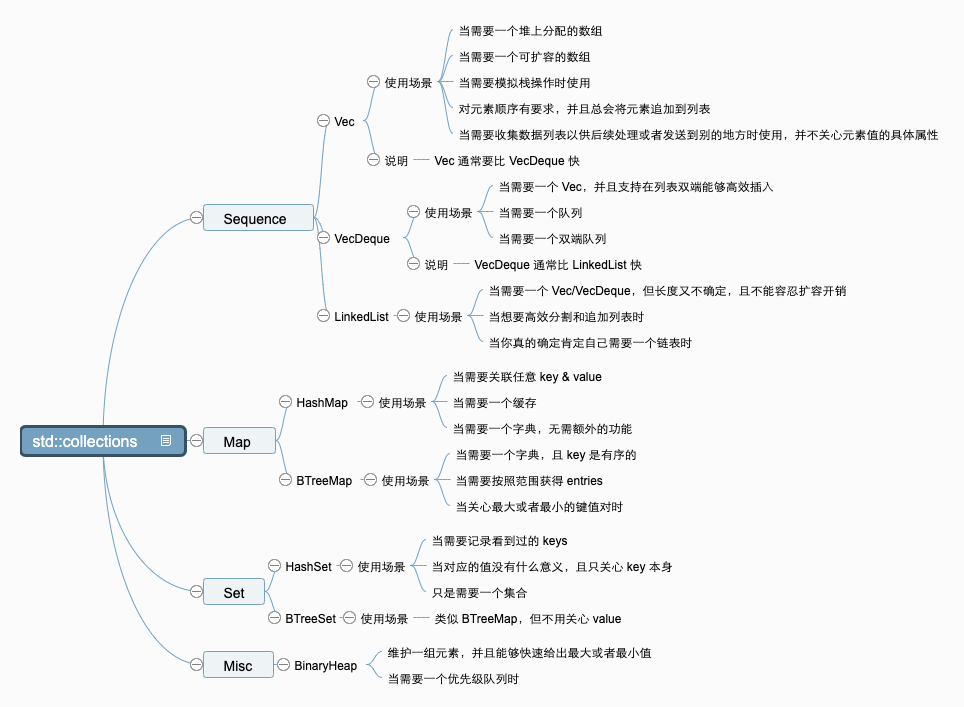
性能对比
- 以下时间复杂度也考虑了因为插入元素而导致扩容带来的时间开销;
- 容器会自动扩容,但是不会自动缩容,提供了
shrink类方法可以手动调用; - 只有
HashMap有可预期的开销,但是极端情况下,也可能会有糟糕的性能问题; - 通常来说,性能方面:
Vec>VecDeque>LinkedList; - 集合类型的操作对应的开销和
HashMpa相同。
Sequence 操作开销
| get(i) | insert(i) | remove(i) | append | split_off(i) | |
|---|---|---|---|---|---|
| Vec | O(1) | O(n-i)* O(n-i) | O(m)* | O(n-i) | |
| VecDeque | O(1) | O(min(i, n-i))* | O(min(i, n-i)) | O(m)* | O(min(i, n-i)) |
| LinkedList | O(min(i, n-i)) | O(min(i, n-i)) | O(min(i, n-i)) | O(1) | O(min(i, n-i)) |
Map 操作开销
| get | insert | remove | predecessor | append | |
|---|---|---|---|---|---|
| HashMap | O(1)~ | O(1)~* | O(1)~ | N/A | N/A |
| BTreeMap | O(log n) | O(log n) | O(log n) | O(log n) | O(n+m) |
高效使用集合
管理容量
许多集合都提供了若干个与 capacity 有关的构造器和方法,方便预先设定容量。对于这类集合,通常是基于 array 构建的,如果让底层数组总是恰好可以容纳当前存储的元素,那效率其实很低,因为每次插入新的元素,都需要扩容。而扩容的开销是比较大的,通常需要申请一个新的内存区域,存放新的数组,然后将之前数组中的元素依次拷贝过去。
多数集合都采用一种摊销申请策略(armortized allocation strategy),通常申请的空间是超过当前实际要存储元素的空间的,这样在新的元素插入时,无需频繁扩容。而当下次又要扩容时,也会继续申请更大的数组空间。这样做可能会浪费一定的内存空间,但是减少了频繁扩容带来的开销,算是一种 trade-off 吧。这样的策略虽然不错,但是更好的策略莫过于使用者提示集合需要的容量,这样底层的数组也许根本不用再次扩容(resize)。
通常情况下,我们可以使用 with_capacity 构造器提示集合需要存储的元素数量(底层的分配策略会参考这个值,但不是说一定会精确分配刚好存储这些元素的内存,依赖于实现细节),如果我们不知道具体的数量,也可以给出一个合理的上限。
在预测到将要插入大量元素时,也可以使用 reserve 系列方法提示集合提前分配好空间。
最后需要注意的一点是,为了更好的性能,集合是不会自动缩容的。当确定不需要包含更多元素,或者确实需要缩减内存占用时,可以调用 shrink_to_fit 方法即可。这样可以将底层数组缩容到恰好可以存储所有元素,节约内存使用。
迭代器
Rust 标准库中有很多数据结构都支持迭代器这种模式,当然在 Python 等语言中我们也见证过迭代器的特色。迭代器提供了一种统一、通用、安全、高效的方式遍历元素。迭代器的内容通常是惰性执行的,也就是只有迭代到那个位置,才需要生成值,无需临时分配空间存储它们。通常使用 for 循环消费迭代器,有些函数也支持接受可迭代的对象参数。
标准库中所有集合都提供了一组迭代器,几乎所有集合都提供这么几个方法:iter, iter_mut, into_iter。
iter 会返回一个迭代器,迭代时会返回元素的不可变引用,并且以对应数据结构的「自然」序依次访问。
1 | let vec = vec![1, 2, 3, 4]; |
iter_mut 和 iter 类似,不过它返回的迭代器在跌代时,得到的是元素的可变引用,这样可以修改元素中的内容。
1 | let mut vec = vec![1, 2, 3, 4]; |
into_iter 用于将集合转换成一个迭代器(这时集合本身所有权就被转移了)。使用 extend + into_iter 是将一种集合转换成另一种集合的主要方法。extend 接收的是 T: IntoIterator 参数,它会在内部自动调用 into_iter。
1 |
|
此外,还可以在迭代器上调用 collect 方法转换成集合。这也是将一种集合转换成另外一种集合的方法。
1 | let a = vec![1, 2, 3, 4]; |
迭代器也支持一些适配方法,例如 map, fold, skip, take, rev 等。比如我们可以使用 vec.iter().rev() 倒序遍历。
Entry API
在使用字典时,一个常见的场景就是根据 key 的存在性来判断是否执行某种操作。我们可以使用字典的 map.entry(&key) 方法,它会在字典中查找 key,并返回一个 Entry enum:
- 返回的是
Vacant(entry):表示 key 并不存在,这时我们只能执行insert操作,从而将值插入到entry。插入完成后,空 entry 就被消费并转化成一个指向被插入值的可变引用了,这样可以在继续对该值进行操作。 - 返回的是
Occupied(entry):表示 key 存在,这样我们可以使用get,insert或者remove等方法。
Entry 的具体定义如下:1
2
3
4
5
6
7
8
9
10
pub enum Entry<'a, K: 'a, V: 'a> {
/// A vacant entry.
Vacant( VacantEntry<'a, K, V>),
/// An occupied entry.
Occupied( OccupiedEntry<'a, K, V>),
}
示例
- 统计字符个数:
1 | let mut count = BTreeMap::new(); |
- 插入复杂 key(对于复杂 key,调用
insert不会更新 key 本身):
1 | use std::cmp::Ordering; |
std::io 文档学习
因为我们需要将数据持久化到磁盘上,所以有必要掌握 I/O 有关的操作。我们可以通过阅读 std::io 模块文档掌握一些基本的 I/O 操作相关的接口、概念等。
Read & Write
有很多类型实现了标准库定义的 Read 和 Write trait,比如 File, TcpStream 等,这样它们都有类似的使用模式,我们可以看看文件的读取操作:
1 | use std::io; |
Seek
实现了 Seek trait 的 reader,我们可以通过 seek 方法控制定位到哪儿进行读取,用法如下:
1 | use std::io; |
BufReader 和 BufWriter
为了避免在读写字节时产生较多的系统调用,我们可以通过 BufReader 和 BufWriter 减少实际调用次数,这两个结构体内部分别封装了 reader 和 writer,并提供了一个 buffer 用于缓冲并提高性能,减少系统调用次数,同时它们还提供了更易于使用的接口。
BufReader 实现了 BufRead trait,可以搭配任意 reader 使用:
1 | use std::io; |
BufWriter 则会将多次写入缓冲到 buffer 中,并在缓冲区满了或者 writer 离开作用域时执行 flush_buf 操作,实现如下:
1 | fn write(&mut self, buf: &[u8]) -> io::Result<usize> { |
使用示例如下:
1 | use std::io; |
标准输入和输出
1 | use std::io; |
可迭代性
std::io 中有很多类型是可迭代的,比如 Lines,用法如下:
1 | use std::io; |
以上列举的是一些常用的场景和使用范式,具体在使用时,可以阅读文档,选择合适的 I/O 操作工具,篇幅有限,就点到为止了。
Serde
Serde 是 Rust 生态中非常重要的通用、高效的序列化(serialization)和反序列化(deserialization)框架,支持任意类型数据结构的序列化和反序列化,支持任意数据格式。
和很多其它语言在运行时序列化数据不同,Serde 充分利用了 Rust trait 系统,任意数据结构都可以实现 Serde 的 Serialize 和 Deserialize 相关的 trait(当然,我们也可以通过 #[derive(Serialze, Deserialize)] 自动生成),这样可以避免运行时反射的开销。
Serde 数据模型 是 Rust 数据结构与序列化数据格式交互的中间 API,我们可以把它当作 Serde 的类型系统,它是 Rust 类型系统的精简版本,总共 29 种。
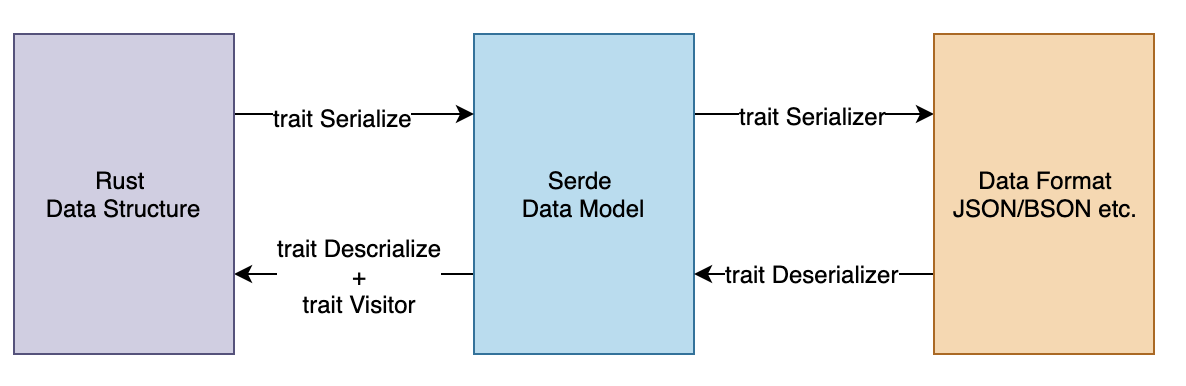
- 序列化:我们需要为 Rust 数据结构实现
Serializetrait(也可以通过derive自动生成),然后通过调用Serializer关联的方法实现到 Serde 数据模型的转换;Serializer则是目标 Data Format 必须要实现的 trait,负责将 Serde 数据模型输出为想要的格式(如 json); - 反序列化:我们需要为 Rust 数据结构实现
Descrializetrait(也可以通过derive自动生成)实现 Rust 类型到 Serde 数据模型的映射,同时会给Deserializer提供一个Visitor;而Deserializer则是具体输入数据格式需要实现的trait,负责驱动Visitor将输入数据转换成 Serde 数据模型。
那如何实现 Serialize/Deserialize 和 Serializer/Deserializer 呢?官方文档提供了一些示例,参见:
使用示例
首先需要在 Cargo.toml 添加 serde 依赖如下:
1 | [dependencies] |
接下来演示下如何将 User 实例序列化为 JSON 格式的字符串,然后再反序列化生产的 JSON 字符串为 User 实例。
1 | use serde::{Serialize, Deserialize}; |