引言
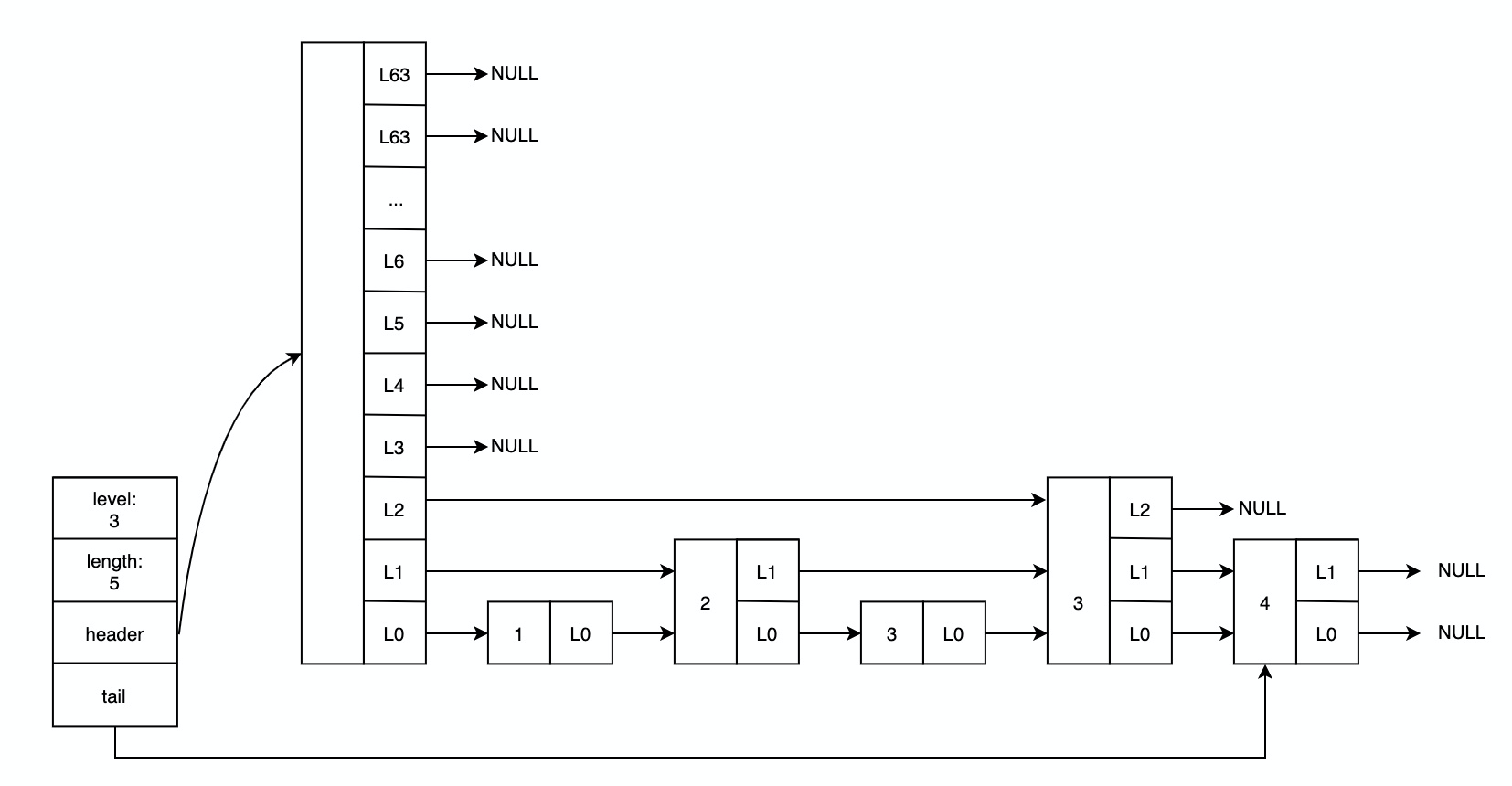
读过 Redis 源码的童鞋,想必会知道 zset 实现时,使用了「跳表」(Skiplist)这种数据结构吧。它的原理非常容易理解,如果对链表比较熟悉,那么也会很容易理解「跳表」的工作原理(核心:有序链表 + 分层)。当然,本文并不会详细讲解「跳表」的工作原理,以及对于 Redis 跳表源码的详细分析。因为已经有前辈们产出了非常丰富的文章来讲解 Redis 跳表,需要的话,推荐阅读 这篇文章 了解更多细节。
读过 Redis 源码的童鞋,想必会知道 zset 实现时,使用了「跳表」(Skiplist)这种数据结构吧。它的原理非常容易理解,如果对链表比较熟悉,那么也会很容易理解「跳表」的工作原理(核心:有序链表 + 分层)。当然,本文并不会详细讲解「跳表」的工作原理,以及对于 Redis 跳表源码的详细分析。因为已经有前辈们产出了非常丰富的文章来讲解 Redis 跳表,需要的话,推荐阅读 这篇文章 了解更多细节。
Redis, REmote DIctionary Server 因其高效、简单、丰富的数据结构支持、高性能、持久化和集群支持等特性得到了程序员们的青睐,并被广泛部署和应用在众多互联网公司。而因为它采用了比较简单的文本协议,使得客户端实现比较简单,因此也拥有众多编程语言实现的客户端;甚至也有一些其它类型的 K-V 数据库兼容了 Redis 协议!
结合我们目前的业务来看,有非常多的场景使用到了 Redis:
当然还有很多场景可以例举,但就我们常使用的 Redis 数据结构来看,主要就是字符串、集合(有序/无序)、字典、列表等。虽说 Redis 给我们提供了其它丰富的内存数据结构,但是我们在生产环境用到的并不多。
Redis, REmote DIctionary Server 因其高效、简单、丰富的数据结构支持、高性能、持久化和集群支持等特性得到了程序员们的青睐,并被广泛部署和应用在众多互联网公司。而因为它采用了比较简单的文本协议,使得客户端实现比较简单,因此也拥有众多编程语言实现的客户端;甚至也有一些其它类型的 K-V 数据库兼容了 Redis 协议!
结合我们目前的业务来看,有非常多的场景使用到了 Redis:
当然还有很多场景可以例举,但就我们常使用的 Redis 数据结构来看,主要就是 string, set, zset, list, hash map。虽说 Redis 给我们提供了其它丰富的内存数据结构,但是我们在生产环境用到的并不多。
Linux Kernel Development 一书中,关于 Linux 的进程调度器并没有讲解的很深入,只是提到了 CFS 调度器的基本思想和一些实现细节;并没有 Linux 早期的调度器介绍,以及最近这些年新增的在内核源码树外维护的调度器思想。所以在经过一番搜寻后,看到了这篇论文 A complete guide to Linux process scheduling,对 Linux 的调度器历史进行了回顾,并且相对细致地讲解了 CFS 调度器。整体来说,虽然比较啰嗦,但是对于想要知道更多细节的我来说非常适合,所以就有了翻译它的冲动。当然,在学习过程也参考了其它论文。下面开启学习之旅吧~