引言
本文内容主要翻译自 Andrew Gallant 的文章 Error Handling in Rust。
如同大多数的编程语言,Rust 中也需要通过特定的方式处理错误。众所周知,目前常见的错误处理方式主要分为两种:
- 异常机制(C#/Java/Python 等);
- 返回错误(Go/Rust 等)。
本文将会综合全面地介绍 Rust 中的错误处理,通过循序渐进地引导,带领初学者扎实地掌握这块知识。如果我们不熟悉标准库的话,我们可能会使用较为愚蠢的方式处理错误,这种会比较繁琐,产生很多样板代码。所以本文会演示如何借助标准库让错误处理更加优雅和简洁。
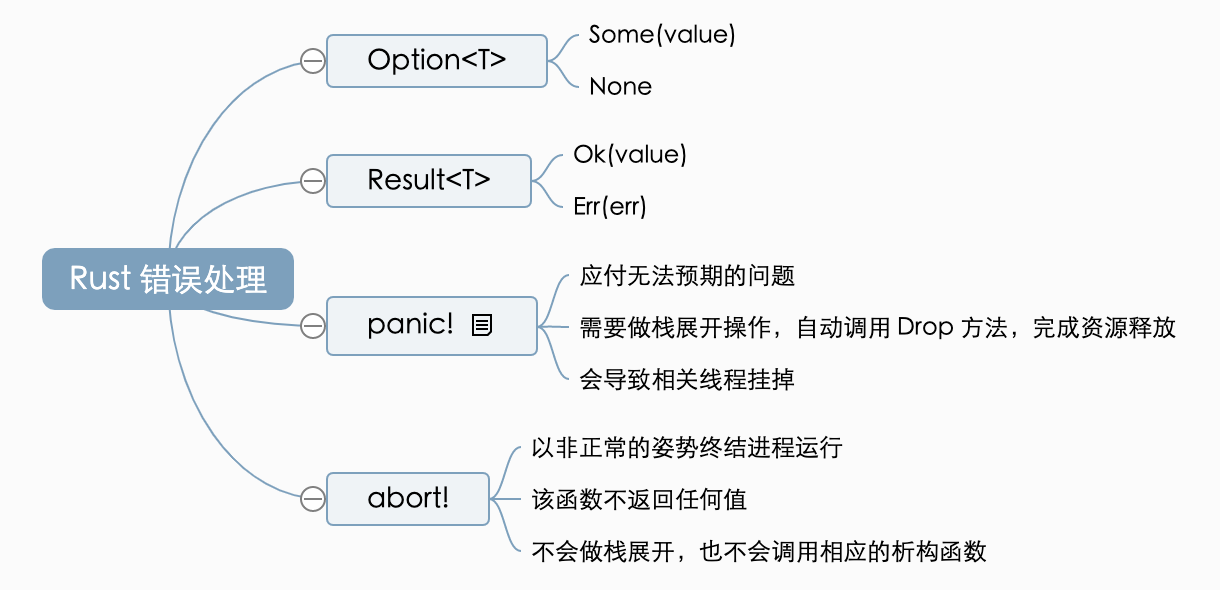
说明
本文的代码放在作者的 博客仓库。
Rust Book, Error Handling 中也有关于错误处理的部分,可以参照阅读。
本文篇幅巨长,主要是因为写了很多关于 Sum Types 和组合子(Combinators)的内容作为开头,逐步讲解 Rust 错误处理方式的改进。因此,如果你认为没有必要的话,也可以略过。以下是作者提供的简要指南:
- 如果你是 Rust 新手,对于系统编程和富类型系统(expressive type systems)不太熟悉的话,推荐你从头开始阅读(如果是完全没有了解过 Rust 的童鞋,推荐先阅读下 Rust Book;
- 如果你从来没有了解过 Rust,但是对于函数式语言很熟悉(看到「代数数据类型(algebaric data types)」和「组合子(combinators)」不会让你感到陌生),那也许可以直接跳过基础部分,从「多错误类型」部分开始阅读,然后阅读「标准库中的 error traits」部分;
- 如果你已经拥有 Rust 编程经验,并且只想了解下错误处理的方式,那么可以直接跳到最后,看看作者给出的案例研究(当然,还有译者给出的实际案例)。
运行代码
如果想要直接运行样例代码,可以参考下面的操作:
1 | git clone git://github.com/BurntSushi/blog |
TL;TR
文章太长,如果没耐心阅读的话,我们可以先来看看关于 Rust 错误处理的一些总结。以下是作者提供的「经验法则」,仅供参考,我们可以从中获得一些启发。
- 如果你正在编写简短的示例代码,并且可能会有不少错误处理的负担,这种场景下可以考虑使用
unwrap(比如Result::unwrap,Option::unwrap或者Option::expect等)。阅读你代码的人应该知道如何以优雅的姿势处理错误(如果 TA 不会,把这篇文章甩给 TA 看); - 如果你正在写一个类似临时脚本一样的程序(quick-n-dirty program),直接用
unwrap也不用觉得羞愧。不过需要注意的是:如果别人接手你这的代码,那可能是要不爽的哦(毕竟没有错误处理不够优雅); - 对于👆的场景,如果你觉得直接用
unwrap不太好(毕竟出错会直接 panic 掉),那么可以考虑使用Box<dyn Error>或者anyhow::Error类型作为函数的错误返回类型。如果使用了anyhowcrate,当使用 nightly 版本的 Rust 时,错误会自动拥有关联的 backtrace; - 要是上面的方法还不行,那么可以考虑自定义错误类型,并且实现
From和Errortrait,从而可以顺利地使用?操作符,让错误处理更加优雅(要是你连From和Errortrait 也不愿意动手实现的话,可以使用 thiserror 来自动生成); - 如果你正在编写一个库,并且可能会产生错误,推荐你自定义错误类型,并且实现
std::error::Errortrait,并且实现合适的Fromtrait,从而方便库的调用者编写代码(因为基于 Rust 的相干性原则(coherence rules),调用者不能为库中定义的错误类型实现From,因此这是库作者的职责); - 学会使用
Option和Result中定义的组合子,有时候只是使用它们可能比较索然无味,但是可以通过合理地组合使用?操作符合组合子来改善代码。and_then,map和unwrap_or是作者比较喜欢的几个组合子。
总结一下流程如下: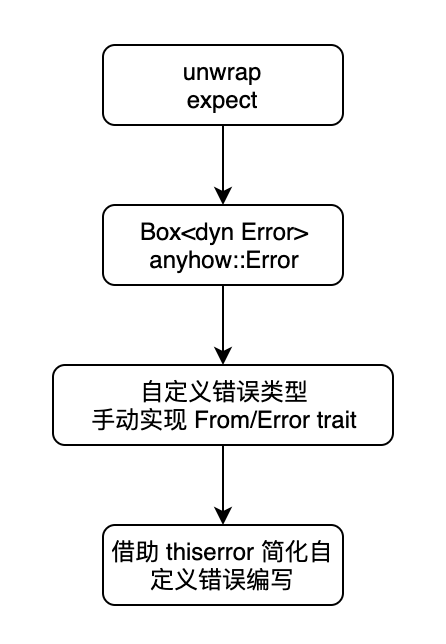
基础知识
错误处理可以看成是利用 分支判断(case analysis) 逻辑来指示一次计算成功与否。优雅的错误处理方式,关键就是要考虑减少显式编写分支判断逻辑的代码,同时还能保持代码的可组合性(就是让调用方有错误处理的决定权,调用方可以在约到错误时 panic 或者只是打印出错误消息)。
保持代码的可组合性非常重要,否则我们可能在任何遇到不可预期的异常时出现 panic(panic 会导致当前的线程栈展开,多数情况下,还会导致整个进程退出)。示例如下:
1 | // file: panic-simple |
如果尝试运行上述代码,程序会直接崩溃,并且会吐出下面的消息:
1 | thread '<main>' panicked at 'Invalid number: 11', src/bin/panic-simple.rs:5 |
下面这个例子,对于用户输入更加不可预知。它预期用户输入一个整数字符串,然后将其转换成整数后再乘以 2,打印出结果:
1 | // file: unwrap-double |
如果我们输入的是 0 个参数(error 1),或者干脆输入不可转换成整数的字符串(error 2),则会导致程序 panic 掉。
Unwrap 详解
unwrap-double 示例中,虽然没有显式地使用 panic,但是它在遇到错误时依然会 panic 掉。这是因为 unwrap 内部调用了 panic。
unwrap 在 Rust 中的意思是这样的:根据提供的计算结果,如果是错误结果,则会直接调用 panic。也许你开始好奇 unwrap 真正的实现了(实现很简单),不过在我们学习完 Option 和 Result 类型后自然就知道了。这两种类型都有关联的 unwrap 方法定义。
Option 类型
Option 类型是标准库定义的枚举类型:
1 | enum Option<T> { |
在 Rust 中,我们可以利用 Option 类型来表达存在性。将这种类型加入到 Rust 的类型系统非常重要,这样编译器会强制使用者处理存在性。下面来看个简单的示例:
1 | // file: option-ex-string-find |
温馨提示:不要在你的代码中使用上述代码,直接使用标准库提供的 find 方法
我们注意到,上述函数在找到匹配的字符后,不会直接返回 offset,而是返回 Some(offset)。Some 是 Option 类型的值构造器,可以将它想象成这样的函数:fn<T>(value: T) -> Option<T>。相应地,None 也是一个值构造器,不过它没有参数,可以将它想象成这样的函数:fn<T>() -> Option<T>。
Oops,看起来有点无聊哦,不过故事还没唠完。我们来看看怎么使用 find 函数,下面就利用它查找文件扩展名:
1 | fn main_find() { |
上述代码对于 find 返回的 Option<usize> 使用了「模式匹配」来执行分支判断。事实上,分支判断是获得 Option<T> 内部值的唯一方式。因此我们必须要处理好 Option<T> 为 None 的情况。
啊喂,等下,在前面提到的 unwrap 是怎么实现的呢?没错,它的内部也使用了分支判断!我们也可以自己定义这样的方法:
1 | enum Option<T> { |
unwrap 为我们封装了分支判断逻辑,方便我们使用。不过由于它内部使用了 panic! 调用,这也意味着它不具备可组合性。
组合 Option<T> 值
在前面的 find 函数编写中,我们使用它来查找文件名的扩展名。但是并非所有文件名都有 .,所以文件名可能并没有扩展部分。这种存在性正是通过使用 Option<T> 类型来表达的。也就是说,编译器会强制我们处理扩展名不存在的情况。我们在上面处理得比较简单,就是打印出没有扩展名这样的提示信息了。
查找文件扩展名是常见的操作,所以有必要将其封装成另一个函数:
1 | // file: option-ex-string-find |
温馨提示:不要使用上述代码,使用标准库中定义的 extension 方法代替
代码很简单,不过需要特别注意的是 find 会强制我们考虑存在性问题。这样一来,编译器就不允许我们「偶然」粗心大意忘记处理文件扩展名不存在的情况。但从另一个方面来看,每次显式低执行分支判断逻辑显得被笨拙。
事实上,在 extension_explicity 中使用的分支判断逻辑是一种常见的模式:map,它可以在 Option<T> 为 None 时返回 None,否则将值传递给指定的函数执行并获取返回结果。
Rust 中可以轻松定义一个组合子,从而将这种模式抽象出来:
1 | // file: option-map |
当然,在标准库中,map 是定义在 Option<T> 上的方法。
有了上面的组合子,我们可以对 extension_explicit 方法简单重构下,从而移除分支判断逻辑:
1 | // file: option-ex-string-find |
另外一种常见的模式是在 Option 值为 None 时,返回一个默认值。举个栗子,你的应用可能会假定文件的默认扩展名是 rs,这样即使 extension_explicit 返回了 None,也可以给个默认的扩展名。
如你所期,这样的分支判断逻辑并非限定于文件扩展名,它可以用于任何 Option<T> 类型:
1 | // file: option-unwrap-or |
使用起来非常简单:
1 | // file: option-ext-string-find |
温馨提示:unwrap_or 在标准库中是定义在 Option<T> 上的方法,所以我们在此使用了标准库的方法。当然,别忘了看看 更通用的 unwrap_or_else 方法哦
还有一个值得特别注意的组合子 and_then,它可以让我们轻松地组合多个不同的计算结果(都使用了 Option<T>)。例如,本节很多代码都在讲如何在指定的文件名中查找扩展名。为此,你需要首先从文件路径中提取出文件名。虽然大多数的文件路径都有文件名,但并非所有的都是这种情况。比如:., .., 或者 /.。
那么,接下来我们要挑战的任务是从给定的文件路径中找到文件扩展名。先来看看显式判断的写法:
1 | // file: option-ex-string-find |
看起来貌似可以使用 map 组合子来减少分支判断代码,不过它的类型并不适合。具体来说,map 接收的函数是专门处理 Option<T> 的内部值。不过此处,我们希望允许调用者通过自定义函数返回另外一个 Option,以下是通用的实现示例:
1 | // file: option-and-then |
现在,我们可以重构 file_path_ext 函数了:
1 | fn file_path_ext(file_path: &str) -> Option<&str> { |
Option 类型还有很多其它组合子,所以推荐去熟悉下这些组合子的使用方式,它们通常可以帮助减少分支判断代码。熟悉了这些组合子后也有助于对 Result 定义的类似方法增进了解,它们有很多类似的方法。
使用 Option 的组合子能够让代码更加优雅,并且减少了很多显式的分支判断逻辑。同时,也给予了调用方更多的可组合性,让调用方能够按照存在性自由处理。而 unwrap 之类的方法则不具备这种优势,是因为它会在 Option<T> 为 None 时直接 panic 掉。
Result 类型
Result 类型也是在标准库中定义的。
1 | enum Result<T, E> { |
Result 类型可以看作 Option 类型的加强版,除了可以像 Option 那样表达存在性,还可以表达可能的错误是什么。通常来说,我们可以通过 error 表明一些计算失败的原因。下面的类型别名和实际的 Option<T> 在语义上是等价的:
1 | type Option<T> = Result<T, ()>; |
以上是让 Result 的第二个类型参数保持为 ()(称为 unit 或者空元组 empty tuple)。() 类型只对应一个值,即 ()(你没👀错,类型和值都使用了同一个术语)。
Result 专门用来表示计算的两种可能的结果。按照惯例,期望的结果当然是 Ok,而另外一种非预期的结果自然是 Err。
正如 Option,Result 类型也有 unwrap 方法实现。我们也可以自定义一个如下:
1 | // file : result-def |
这个基本和 Option::unwrap 的定义是一样的,不过它在 panic! 时会带上错误值。这样调试起来就更简单些了,不过这也要求我们给 E 参数加上 Debug trait 限定。由于绝大多数的类型都应该满足 Debug 限定,所以这样做在实践中也没什么问题。
下面,来看个例子。
解析整数
Rust 标准库让字符串转整数非常容易:
1 | // file: result-num-unwrap |
此处,我们需要对使用 unwrap 的地方保持怀疑的态度。例如,当输入的字符串不能转换时,就会发生 panic:
1 | thread '<main>' panicked at 'called `Result::unwrap()` on an `Err` value: ParseIntError { kind: InvalidDigit }', /home/rustbuild/src/rust-buildbot/slave/beta-dist-rustc-linux/build/src/libcore/result.rs:729 |
这看起来很不优雅,如果 panic 发生在我们使用的库中,自然会更加烦恼。所以,我们应当尝试在函数返回错误,让调用方自由决定做什么。这就意味着要修改 double_number 的返回类型。但是要改成什么好呢?这就需要我们来看看标准库中定义的 parse 签名了:
1 | impl str { |
Emm,至少我们知道需要使用 Result 类型了。当然,也可能返回一个 Option 类型。毕竟,字符串要么可以转成数字,要么转换失败,不是吗?看起来挺合理,不过内部实现需要区分不能转换字符串为整数的原因。因此,使用 Result 会更加合理些,因为这样我们可以提供更多的错误信息,而不仅仅是「存在与否」。
接下来看看,我们怎么指定返回类型呢?上面的 parse 方法是能够处理在标准库中定义的所有数据类型的泛型版本。我们当然也可以让我们的函数变成泛型版本,不过目前为了简单起见,只关心 i32 类型。
我们需要看看 FromStr 的实现,关注下它的关联类型Err。在我们这里,关联错误类型为 std::num::ParseIntError。最终,我们可以将函数重构如下:
1 | // file: result-num-to-unwrap |
这样看起来就好多了,但是我们还是写了很多代码,尤其是分支判断逻辑又出现了。那该怎么办呢?Result 也定义了很多关联的组合子,所以此处我们可以使用 map:
1 | // file: result-num-no-unwrap-map |
Option 中定义的很多组合子,类似 unwrap_or, and_then 在 Result 类型中都可以使用。此外,Result 还有第二个 Err 类型,所以还有一些专门关联错误类型的组合子,例如 map_err 和 or_else 等。
Result 类型别名
看标准库中,经常会发现类似 Result<i32> 这样的类型。但是,我们定义的 Result 类型明明有两个类型参数呢!那是怎么做到只需要指定一个类型的?关键点就在于可以定义一个 Result 类型别名,这样可以把某个具体的类型固定下来。通常,被固定的类型是错误类型。接下来,我们可以为上面定义的 Result 类型做个别名,示例如下:
1 | // file: result-num-no-unwrap-map-alias |
为什么需要这么做呢?假如我们有很多函数都要返回 ParseIntError 类型,通过类型别名就可以省心很多,不用到处写 ParseIntError 了。
在标准库最典型的应用就是 io::Result 了,通常的用法是 io::Result<T>。
小插曲:unwrap 并非邪恶
虽然上面花了很多篇幅在讲怎么避免使用 unwrap 或者可能导致 panic 的写法,通常情况下,我们是应该这么做。然而,有时候使用 unwrap 依然是明智的。下面是一些可以考虑直接使用 unwrap 的场景:
- 在示例代码、临时脚本(qunk-n-dirty code)中。有时候我们在写的临时脚本程序,对于错误处理并不需要严肃处理,所以即便使用
unwrap也没什么毛病; - 想要通过 panic 表明程序中存在 bug。当你需要在代码中阻止某些行为发生时(比如从空的 stack 中弹出元素),可以考虑使用
panic,这样可以暴露出程序中的 bug。
可能还有很多其它的场景,不在此一一列举了。另外,当我们使用 Option 时,通常使用它的 expect 方法会更好,这样可以打印出自定义的有意义的错误消息,也不至于在 panic 的时候手足无措。
归根结底,作者的观点是:保持良好的判断力。对于任何事情都需要权衡,我们需要根据场景来判断使用什么方法。
处理多种错误类型
到目前为止,我们学习了很多关于使用 Option<T> 或 Result<T, SomeError> 处理错误的方式。但是,如果 Option 和 Result 同时出现呢?又或者我们同时遇到 Result<T, Error1> 和 Result<T, Error2>?接下来的挑战就是处理多种组合的错误类型,这也是本文的核心内容。
组合 Option 和 Result
至此,我们已经学习了很多关于 Option h 和 Result 的组合子,并且可以使用这些组合子将不同的计算结果组合起来返回,不需要显式地编写分支判断逻辑。
然而,现实代码并非如此干净。有时,我们会有 Option 和 Result 类型的混合,这时候我们又要退化到显式地编写分支判断逻辑了吗?或者有没有可能继续使用组合子呢?
现在,让我们复习下前面提到的例子:
1 | use std::env; |
鉴于我们已经学会使用 Option, Result 以及相关的组合子了,那我们可以尝试重构下上述代码,这样可以合理地处理错误,并且在发生错误时不要轻易地 panic。
这里比较特别的是,argv.nth(1) 返回的是 Option,而 arg.parse() 则返回 Result。显然,它们二者不可组合。这时,我们通常可以将 Option 转换成 Result。在我们的例子中,缺少命令行参数将会无法正常工作。我们现在只需要使用 String 来描述错误:
1 | // file: error-double-string |
在这个例子中有几个新的知识点值得介绍。第一点是使用 Option::ok_or 组合子:它可以将 Option 转换成 Result,此处需要我们指定错误消息。下面来看看它的定义:
1 | // file: option-ok-def |
这里使用的另一个组合子是 Result::map_err,它类似于 Result::map,不过它将传入的函数应用在 error 部分。
这里之所以使用 map_err,是因为有必要让错误类型保持不变(因为我们还会使用 and_then)。因为我们需要将 Option<String>(来自 argv.nth(1))转换成 Result<String, String>,所以也要将来自 arg.parse() 的 ParseIntError 转换成 String。
组合子的限制
IO 和解析命令行输入是很常见的操作,所以我们将会继续讲一些和 IO 有关的例子来展开错误处理。
先从简单的例子开始吧,假设我们需要读取一个文件,将其中每一行转成数字形式,然后再乘以 2 后输出。
虽然之前强调不要随意使用 unwrap,但是我们可以在最开始时候临时使用它。这样我们可以集中精力解决问题,而非处理错误。先简单编写出来,后面在重构它,完善错误处理部分。
1 | // file: io-basic-unwrap |
温馨提示:这里使用了和 std::fs::File::open 相同的类型绑定 AsRef<Path>,这样可以非常优雅地接受任何类型的字符串作为路径。
这里有三种可能的错误会发生:
- 打开文件;
- 从文件中读取数据;
- 将文本数据转换成数字。
前两个错误可以使用 std::io::Error 类型(这个可以从 std::fs::File::open 和 std::io::Read::read_to_string 返回错误可以得知)表示。第三个错误则可以用 std::num::ParseIntError 类型。需要注意的是,io::Error 类型在标准库中使用很广泛。
接下来,开始重构 file_double 函数吧,这样可以让函数返回值可以和其它部分组合,保证在发生上述错误时,不要直接 panic 掉。这也就意味着当任何操作失败时,函数需要返回具体的错误。现在的问题是,之前写的 file_double 函数返回值是 i32,并不会包含任何错误信息。所以我们需要将返回值从 i32 转换成别的类型。
首先我们要做的决策是:我们是应该使用 Option 还是 Result 呢?当然,我们可以直接使用 Option,这样报错时,只需要返回 None 即可。这样看起来不错,并且也比直接 panic 要好得多,但我们还可以做得更好。我们还可以使用 Result<i32, E> 来表达可能出现的错误。但是这里的 E 又是什么呢?由于存在两种类型的错误可能发生,我们需要将它们转换成通用的类型。一种可选项就是 String,下面来看看修改后的效果:
1 | // file: io-basic-error-string |
上面的代码看起来还是有些凌乱。因为我们需要将返回类型统一为 Result<i32, String>,这样就不得不使用合适的组合子。上面是使用了 and_then, map 和 map_err。
掌握组合子的使用很重要,不过它也有些限制,还可能把代码弄得很凌乱。接下来看另外一种方式:提前返回。
提前返回
首先我们将上一个例子改造成提前返回的模式。由于我们难以在 file_double 中的闭包中直接返回,所以需要改成显式分支判断逻辑。
1 | // file: io-basic-error-string-early-return |
关于是使用组合子好,还是上面的写法好,仁者见仁。当然,上面的写法明显更加直观易懂,当发生错误后直接终止函数执行,返回错误接即可。
看起来像是退步了一样,先前我们一再强调优雅错误处理的关键就是减少显式的分支判断逻辑,显然这里我们违背了之前的原则。不过,我们还有别的办法来解决显式分支判断过多的问题,下面来看看吧。
使用 try! 宏或者 ? 操作符
早期版本的 Rust 中(1.12 版本及以前),错误处理的基石之一是 try! 宏。try! 类似于组合子,抽象了分支判断逻辑,同时也抽象了控制流(control flow)。这样就可以应用提前返回模式了。
以下是一个简单版本的 try! 宏:
1 | // file: try-def-simple |
我们来看看借助于 try! 改造后的效果:
1 | // file: io-basic-error-try |
而在 Rust 1.13 之后,try! 就被 ? 操作符替代了。改写后如下:
1 | // file: io-basic-error-question |
自定义错误类型
在深入学习标准库 error trait 之前,接下来我们要做的是将 Result<i32, String> 中的 String 替换成自定义 Error。因为直接使用 String 有如下两个缺点:
- 容易污染代码,搞得到处都是错误消息字符串;
- 字符串会丢失信息(比如错误类型,错误来源等)。
举个例子,io::Error 嵌套了 io::ErrorKind,它是结构化的数据,用来表示 IO 操作时具体的错误。这一点非常重要,因为我们可能需要针对不同的错误做出不同的响应。所以有了 io::ErrorKind 后,调用方就可以基于具体的错误类型进行处理了,而这显然要比从 String 中提取错误原因更加严格。
所以接下来,我们要定义自己的错误类型,尽可能避免将下层错误给丢掉,这样如果调用方需要查看错误详情,也不至于无计可施。
我们可以通过 enum 来定义包含多种错误的类型,示例如下:
1 | // file: io-basic-error-custom |
紧接着,我们只需要将之前例子中的 String error 替换成自定义的 CliError 即可:
1 | // file: io-basic-error-custom |
标准库中的错误处理 trait
标准库定义了两种错误处理必备的 trait:
std::error::Error,专门用于表示错误;std::convert::From,更加通用的接口,用于两种类型之间的转换。
Error trait
Error trait 的定义如下:
1 | use std::fmt::{Debug, Display}; |
这个 trait 是非常通用的,也是所有表示错误的类型都要实现的 trait。总的来说,这个 trait 可以让我们做这么几件事情:
- 获取错误表示的
Debug表示(需要实现std::fmt::Debugtrait); - 获取错误的
Display表示(需要实现std::fmt::Displaytrait); - 获取错误的简要描述(
description方法); - 获取错误链(可以通过
cause方法获得)。
由于所有的错误都实现了 Error trait,那我们就可以将错误表示成 trait object 了(比如表示成 Box<dyn Error> 或者 &dyn Error)。
接下来,我们可以为 CliError 实现 Error trait:
1 | // file: error-impl |
From trait
先来看看 From trait 的定义吧:
1 | trait From<T> { |
看起来超级简单吧,From 非常有用,它提供了一种通用的方式将一种类型转换成另一种类型。可以来看看几个简单的例子:
1 | let string: String = From::from("foo"); |
好吧,看起来字符串之间的转换使用 From 非常便捷。但是关于错误的转换呢?事实上关于错误有这么一个 From 转换实现:
1 | impl<'a, E: Error + 'a> From<E> for Box<dyn Error + 'a> |
这就一折任意实现了 Error trait 的类型,都可以转换成 Box<dyn Error> trait object。看起来并没有多么让人吃惊,但是很实用。来看看下面的例子:
1 | // file: from-example-errors |
上面的 err1 和 err2 的类型都是相同的类型,这里都是 trait object。对于编译器而言,它们的底层类型已经被移除了。上面实用 From::from 的模式非常重要,它为我们提供了一种可靠且一致的方式将错误转换成相同的类型。
是时候复习下我们的老伙计 try! 和 ? 操作符了。
try! 和 ? 内部实现
try! 的内部实现并非和前面提到那样简单,在内部还执行了额外的转换操作:
1 | macro_rules! try { |
? 的工作原理也是类似的,只是定义上有些许不同,看起来可能像下面这样:
1 | match ::std::ops::Try::into_result(x) { |
让我们来回忆下之前用于读取文件并转换成整数的代码:
1 | use std::fs::File; |
既然我们已经知道 ? 实现中涉及了 From::from 调用,即错误类型的自动转换, 那么我们将函数的返回错误使用 Box<dyn Error> 表示,从而将错误转换成 trait object:
1 | // file: io-basic-error-try-from |
现在,我们已经越来越接近完美的错误处理模式了。由于 ? 操作符的加持,为我们节省了很多代码,同时提供了如下几种能力:
- 分支判断;
- 控制流;
- 错误类型转换。
但是,还有一个小瑕疵没有解决。Box<Error> 是模糊的,我们没法得知原先的错误类型,虽然相比于 String,我们可以通过 description 和 cause 获取到更详细的错误信息。接下来,我们需要解决这个小瑕疵。
组合自定义错误类型
首先要为我们的 CliError 实现 From 转换,这样在使用 ? 操作符时,就可以完成错误类型的自动转换了。
1 | impl From<io::Error> for CliError { |
然后将 file_double 重构如下:
1 | // file: io-basic-error-custom-from |
如果我们想要让 file_double 将字符串转换成 float,就需要添加一个新的错误类型:
1 | enum CliError { |
然后实现错误类型转换 trait 即可:
1 | impl From<num::ParseIntError> for CliError { |
给库作者的一些建议
如果我们需要在自己的库中报告自定义的错误,那可能就需要自定义错误类型。我们可以决定要不要暴露错误实现(类似 ErrorKind)或者隐藏实现(类似 ParseIntError)。不管怎样,都要比直接用 String 表示错误更加科学。
对于我们的自定义错误,都应当实现 Error trait,这样也为库的使用者提供了错误组合的灵活性,同时也可以让用户有从错误中获得详细信息的能力(需要实现 fmt::Debug 和 fmt::Display)。
此外,我们也需要为自定义错误类型提供 From 的实现,这样就可以组合更多详细错误了。比如,csv::Error 就提供了来自 io::Error 和 byteorder::Error 的转换实现。
最后,我们也可以根据情况定义 Result 类型别名。
案例研究:阅读人口数据的小程序
接下来,将构建一个命令行程序,用于查询指定地方的人口数据。目标很简单:接收输入的位置,输出关联的人口数据。看起来挺简单,不过还是有很多可能出错的地方!
下面我们需要使用的数据来自 数据科学工具箱,可以从 这里 获取世界人口数据,或者从 这里 获取美帝人口数据。
它在 GitHub 上
代码托管在 GitHub 上,如果已经安装好 了 Rust 和 Cargo,可以直接克隆下来运行:
1 | git clone git://github.com/BurntSushi/rust-error-handling-case-study |
不过下面我们将一点点地编写好这个程序~
配置
首先创建新的项目:cargo new --bin city-pop,然后确保 Cargo.toml 类似下面这样:
1 | [package] |
紧接着就可以编译运行了:
1 | cargo build --release |
参数解析
我们使用的命令行解析工具是 Docopt,它可以从使用帮助中生成合适的命令行解析器。完成命令行解析后,就可以将应用参数解码到相应的参数结构体上了。接下来看看下面的示例:
1 | extern crate docopt; |
好啦,开始撸代码吧。依据 Docopt 的文档,我们可以使用 Docopt::new 新建一个 parser,然后使用 Docopt::decode 将命令参数解码到一个结构体中。这些函数都会返回 doct::Error,我们先显式地编写分支判断逻辑吧:
1 | // These use statements were added below the `extern` statements. |
看起来还是不够简洁,一种可以改进的方式是编写一个宏,将消息打印到 stderr 后退出:
1 | macro_rules! fatal { |
此处使用 unwrap 是可以的,因为一旦执行失败,就意味着程序无法向 stderr 写入了。
代码看起来好多了,不过还是有一处显式分支判断逻辑:
1 | let args: Args = match Docopt::new(USAGE) { |
谢天谢地,docopt::Error 类型定义了一个 exit 方法,这样我们就可以抛弃上面的 match 模式匹配,换用组合子编写出更加紧凑的代码了:
1 | let args: Args = Docopt::new(USAGE) |
编写业务逻辑
我们需要解析 csv 数据,并将符合条件的行打印出来即可。接下来看看怎么完成这个任务:
1 | // This struct represents the data in each row of the CSV file. |
来来来,我们来梳理下有哪些错误(看看 unwrap 调用的地方):
fs::File::open会返回io::Error;csv::Reader::decode每次解码一条记录,该操作会产生csv::Error(参见Iterator实现中关联的Item类型);- 如果
row.population为None,那么调用expect会导致 panic。
那还有别的错误吗?万一城市不存在呢?类似于 grep 的工具会在这种情况下返回错误码,所以我们也可能需要这样做。
接下来,我们来看看两种处理这些错误的方式。先从 Box<dyn Error> 开始吧~
使用 Box<dyn Error> 处理错误
Box<dyn Error> 最大的好处是简单易用,我们不需要为错误类型实现任何 From 转换。但缺点也在前面提过,它由于是一个 trait object,会丢失底层的错误类型。
接下来开始我们的重构吧,首先需要把我们的业务逻辑抽到一个单独的函数中处理,依然保留 unwrap 调用,同时对于没有人数的城市,我们把那行忽略即可。
1 | struct Row { |
虽然我们已经移除了一处 expect(它是 unwrap 更优雅的变种),但我们仍然需要处理搜索结果的存在性问题。
为了能够用合适的方式处理错误,需要对代码做如下几处修改:
1 | fn search<P: AsRef<Path>> |
这里我们使用 ? 替代了 unwrap 调用,但这段代码还有一个问题:我们在这里使用的是 Box<Error + Send + Sync> 而非 Box<Error>。之所以选择这样做,是为了方便将字符串转换成错误类型。看到下面的 From 转换实现就可以明白了:
1 | / We are making use of this impl in the code above, since we call `From::from` |
现在我们已经知道怎么使用 Box<Error> 处理错误了,接下来我们尝试另外一种方式:自定义错误类型。
从 stdin 中读取
为应用添加从 stdin 读取的支持非常简单,我们只需做出如下两处调整即可:
- 调整程序可以接收一个城市参数,而人口数据可以从
stdin中读取; - 修改
search函数,这样可以接收一个可选的路径,当为None时,需要从stdin中读取数据。
我们先来调整下命令行结构体和使用帮助:
1 | static USAGE: &'static str = " |
search 的修改更加特别,csv crate 可以基于任何实现了 io::Read 的类型构建 parser。但我们如何才能在两种类型上使用相同的代码呢?我们尝试下使用 trait object:
1 | fn search<P: AsRef<Path>> |
使用自定义错误类型
根据前面的分析,有三种类型的错误,所以我们的自定义错误类型如下:
1 | enum CliError { |
在我们正式使用 CliError 前,还需要实现一组 From,用于错误类型转换:
1 | impl From<io::Error> for CliError { |
接下来完成 search 函数的改造:
1 | fn search<P: AsRef<Path>> |
独创案例研究:新冠数据查询
2020 年的新冠肺炎对人类社会来说,是一场突如其来的打击。接下来我们写一个简单的命令行程序,用来根据指定的国家返回感染人数、死亡人数等数据。可以在这个仓库查看完整源码。
数据是在 2020 年 4 月 22 日从知乎上获得的,整理成了 csv 文件,可以在 此处 查看。
这里我们使用了的命令行处理工具是 structopt,它是基于 clap 封装而成,可以将命令行参数通过一个结构体来表达,并且通过过程宏来生成 clap 命令行解析器,使用起来非常简单。下面来看看命令行参数结构体定义:
1 | use structopt::StructOpt; |
紧接着是我们需要根据 csv 文件编写用于表达记录的结构体,具体代码如下:
1 | /// Record represents a row in the target csv file |
错误类型的话,在上面的示例也做过分析,基本类似,所以这里直接给出自定义错误类型如下,不过为了避免手动实现 Error trait,以及一些 From 实现,这里使用了 thiserror,这样可以让代码更加紧凑:
1 |
|
然后是我们的核心业务逻辑 search 函数实现:
1 | fn search<P: AsRef<Path>>(input: &Option<P>, country: &str) -> Result<Record, CliError> { |
最后在 main 函数中把以上串起来即可:
1 | fn main() { |
代码写完后,我们可以通过运行 cargo run -- --help 查看使用帮助如下:
1 | covid 0.1.0 |
使用示例如下:
1 | $ cargo run -- -d=assets/covid-19-infections-20200422.csv 美国 |
总结
好啦,终于翻译完了,内容很多,不过我们只要把握好主线即可快速掌握作者想要给我们传达的信息。